

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Variation in throughput
AIM
WAN tests of throughput show wildly varying throughput. Possible causes of this are:
- the effect of cross traffic
- misconfiguration of iperf
- bugs of iperf in reporting throughput
Method
iperf and udpmon tests will be conducted on back to back machines for a long duration to determine the degree of variation of throughput values.
It was found that the optimial buffer size of the back to back setup between pc55 and pc56 is approximately 280k. This experiment will conduct a series of tests with the range 40k to 1080k. It was also found that the optimal duration of the tests were 8 seconds. Run 1 will confirm this duration with and the optimal buffer size.
Tests will be from pc55 to pc56. pc56 is set with a window size of 2048k (the max allowed).
Run 1
Run date: Wed 10th July 2002.
AIM: to discover the optimal duration of testing and the optimal buffer size.
To find the optimal buffer size, we alter the buffer size with the reciever set to large windows and conduct tests for a long duration (30sec). Repeated 3 times, we determine the maximal throughput and choose a window size at the plateau of the throughput.
We set the reciever as pc56: with a socket buffer size set to 2048k.
We have to take into consideration that the maximal amount of data transferable is 4gigabytes = 32gigabits. That means that if we can transfer at 1000mbits a second, we can only actually transfer for 32 seconds.
buffer sizes {16, 32, 64, 96, 128, 160, 192, 224, 256, 288, 320, 352, 384, 416, 448}k.
The kernel was set to
tcp_rmem: 4096 131072 8388608
tcp_wmem: 4096 131072 8388608
on both pc55 and pc56
results on graph linked.
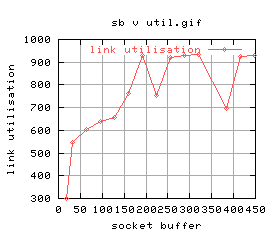 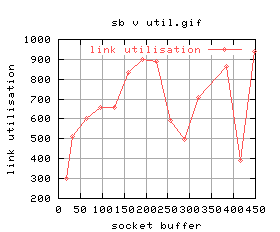 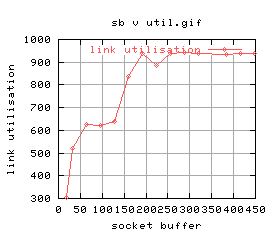 |
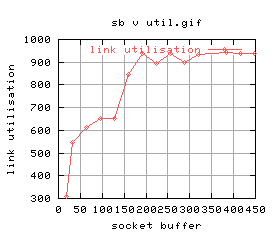 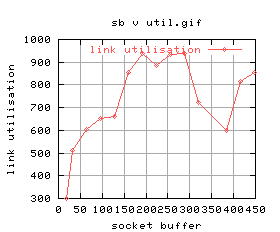 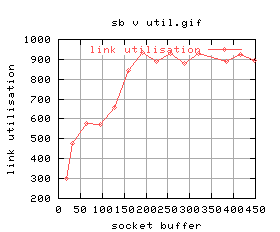 |
There's quite a lot of variation for some of the graphs. For example, the 5th one shows that for higher buffer sizes, the performance is worse. The time at which those tests were conducted, the system was being loaded quite highly by GridNM conducting it's polling.
Run 2
AIM: to determine from the optimal value, an optimal transfer time for the test.
It was found from the above experiment that the optimal socket buffer size was: 200k. With this value set, we change the duration of the test between 1 and 30 seconds. {1,2,5,8,10,12,15,18,20,25,30}k.
results - click on relevant graph.
=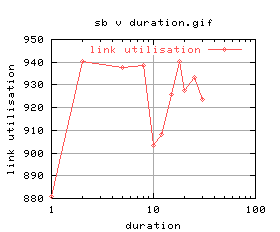 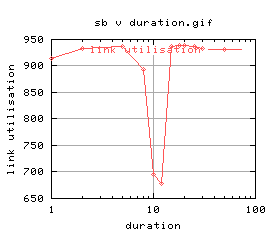 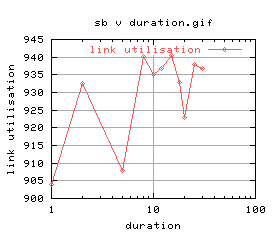 |
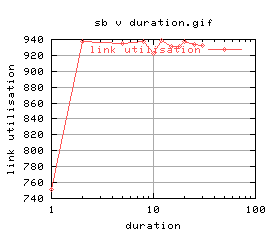 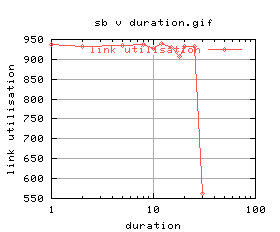 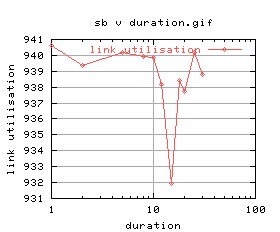 |
There's quite a lot of variation on the graphs - again this was most likely due to cpu load. An investigation into the effects of cpu load will follow as soon as i can work out how to control the cpu load on unix.
Anyway, ignoring the really bad plots (2 and 3), duration of 5 and 8 look okay. Suggest 5 seconds.
Run 3
Anyway, let's do this properly - running all durations between 1 and 10 seconds:
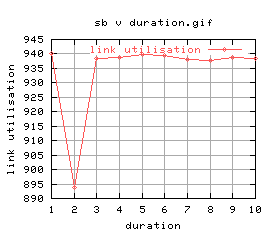 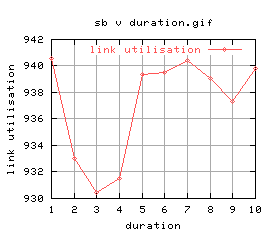 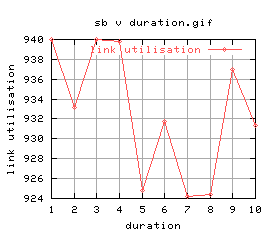 |
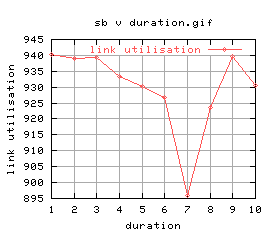 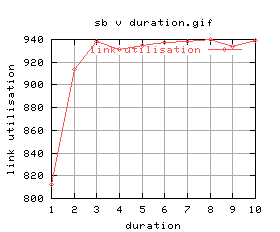 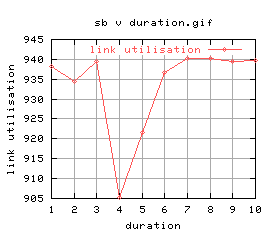 |
Quite a lot of variation again (maybe i should do these without background cpu load?) Anyway, there doesn't seem to be much between them, and the graphs aren't that good... let's just stick with 5 seconds.
It was found that the optimal run duration was 5 seconds.
Run 2
Using the GridNM architecture, we define pc55 and pc56 in xml files and a tools.xml file that defines various iperf values with udpmon and ping. It was also set to monitor various other values such as the linux snmp details and memory and cpu utilisations.
NB: Due to problems with iperf, the buffer sizes stated in tools.xml are half that of the value that is required.
With various socket buffer sizes of {40,120,200,280,360,440,520,600,680,760,840,920,100}k, we run the tests every 5 minutes for a whole night. (about 14 hours). We also monitor other tools such as udpmon and ping. We want to see the variations with time, so we also leave the machine to run GridNM. Every hour, the server starts running it's tests. Whilst the tests aren't particular intensive on the server, the polling and processing of the information is potentally. (we will run one without the cpu load some other time). The GridNM server is on pc55 (ie the source).
This was run on the night of 10th July 2002.
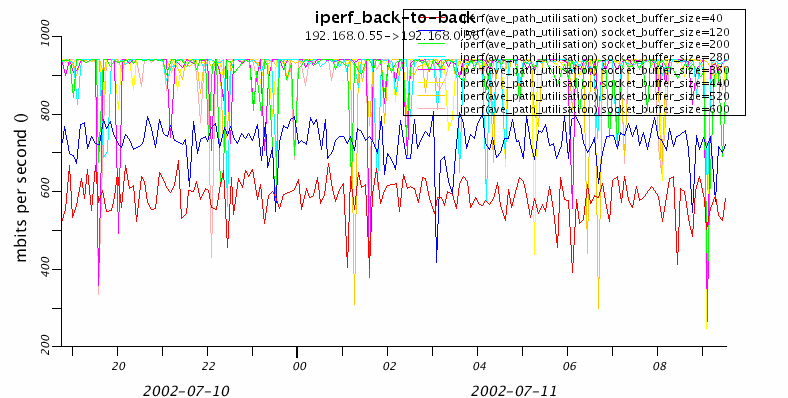
So that is the variation of throughput in time. There is a GridNM poll every hour, so there is a high cpu load on the hour every hour for about 5 minutes or so. So the chances are that it doesn't catch it.
This is probably better represented as a frequency chart:
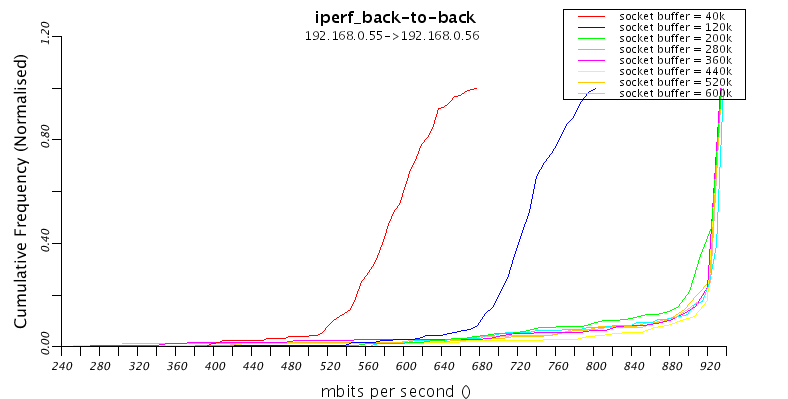
So this shows the cumulative frequency of the different socket buffer sizes. Notice that there's not much variation. And the plots for socket buffers greater and equal to 200k are pretty much the same. So there's no tailing off of throughput for larger socket buffer sizes... dammit. Seems like that only exists for the WAN tests then...
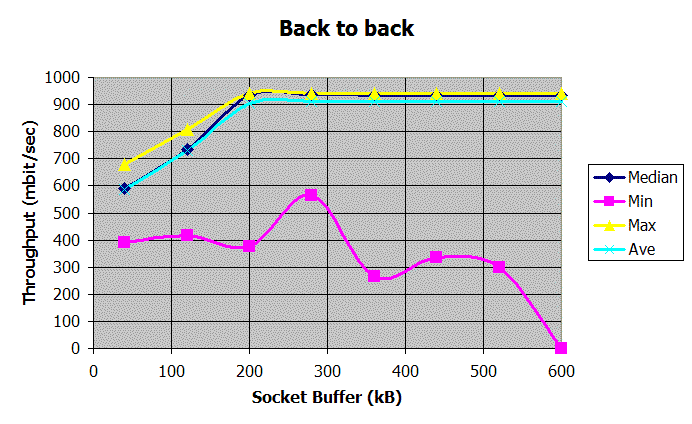
Excel spread sheet of results here.
This shows the actual performance of the socket buffer for all the 178 samples for each socket buffer size. As you can see, the result is almost exactly to that of theory.
| Wed, 23 July, 2003 13:07 |
Room D14, High Energy Particle Physics, Dept. of Physics & Astronomy, UCL, Gower St, London, WC1E 6BT