

IP Routing
IP Multicast traffic for a particular (source, destination group) pair is transmitted from the source to the recievers via a spanning tree that connects all the hosts in the group. This 'state' is stored on routers on the participating IP Multicast network. Different IP Multicast routing protocols use different techniques to construct these multicast spanning trees. Once the tree is constructed, all multicast traffic is distributed over it.
Distribution Trees
There are two basic types of multicast distribution tree; source trees and shared trees. Both types are loop free and messages are replicatedonly where the tree branches. As members of multicast groups can join or leave at any time, the distribution tree must be dunamically updated. When all the active receivers on a particular branch stop requesting the traffic for a particular multicast group, the routers prune that branch from the distribution tree and stop forwarding traffic down that branch. If one reciever on that branch becomes active and requests the multicast traffic the router will dynamically modify the distribution tree and start forwarding traffic again.
Source Trees
The simplest form of a multicast distribution tree is a source tree with its root at the source and the branches forming a spannign tree through the network to the receivers. As source trees uses the shortest path through the network, it is also referred to as a shortest path tree (SPT). Routers keep (S,G) states so packets can flow from the source to all recievers. The tree is build on demand, in response to data arrival. (S is the source IP address, G is the multicast group address).
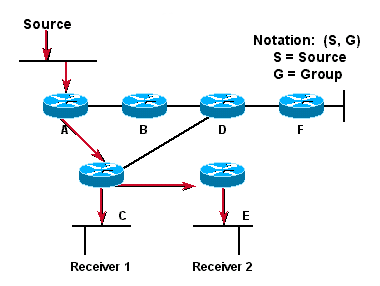
The above diagram shows a (S,G) of (192.1.1.1,224.1.1.1). This notation implies that a separate SPT exists for each individual source sending to each group. For example, if Host B is also sending traffic to the multicast group 224.1.1.1 and Hosts A and C are receivers, then a separate (S,G) SPT would exist with the notation (192.2.2.2,224.1.1.1). in the above example, the shortest path between Source and Receiver 1 is via Routers A and C, whilst the shortest path between Source and Receiver 2 is the addtional hop via Router E.
The construction of the tree requires knowledge of the source locations which means that for every source sending to a group, there is a corresponding SPT. This is learned when data arrives at each depth of the tree.
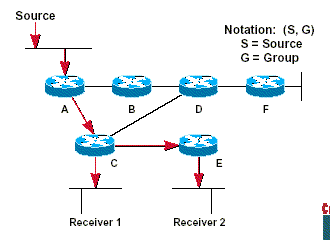
SPT have the advantage of creating the optimal path between the source and the recivers. this will gurantee the ninimum amount of network latency for forwarding multicast traffic. This optimisation comes with a price - the routers must maintain path information for each source. In a network that has thousands of sources and thousands of groups this can quickly become a resource issue on the routers. Memory consumption from the size of teh multicast routing table is a a factor that network designers must take into consideration.
Shared Trees
Shared trees use a single common root places at some chosen point in the network. The shared root is called a Rendezvous Point (RP). This router keeps (*,G) state information so packets can flow from the root of the tree to all receivers. Where the * means that multicast traffic is forwarded down the Shared Tree accordingto just the Group address, regardless of the source address. There is an explicit control for the construction of the tree.
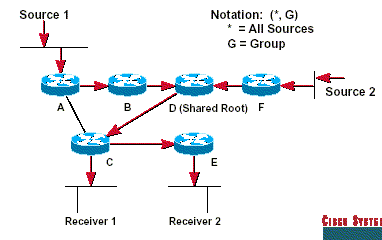
Before traffic can be send down the Shared Tree, it must first be sent to the Root of the Tree. In classic PIM-SM, this is accomplished by the RP joining the Shortest Path Tree back to each source so that the traffic can flow to the RP and from there down the shared tree. In order to trigger the RP take this action, it must somehow be notified when a source goes active on the newtork. In PIM-SM, this is done by first-hop-routers (ie the router directly connected to an active source) seding special Register message to the RP to inform it of the active source.
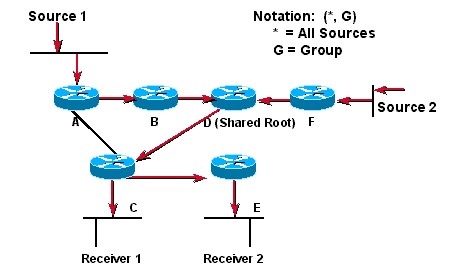
The above diagram, the RP has been informed of Sources 1 and 2 being active and has subsequently joined the SPT to these sources. It shows the shared tree for the group 224.2.2.2 with the root located at router D. When using a shared tree, sources must send their traffic to the root and then the traffic is forwarded down the shared tree to reach all receivers.
In this example, multicast traffic from the sources, Host A and D, tracels to the root (Router D) and then down the shared tree to the two receivers, Hosts b and C. Since all the sources in the multicast group use a common shared tree, a wildcard notation written as (*,G) represents the tre. In this case, * means all sources, and the G represents the multicast group. Therefore, the shared tree shown in the figure above would be written as (*,224.2.2.2).
In order to build a tree under this regime, we need to know where the core (RP) is. This can be done in three possible ways; learned dynamically in the routeing protocol (Auto-RP, PIMv2), configured in the routers or found through the use of a directory service.
In sparse mode protocols, the location of the the source is discovered when data arrives on the shared tree (in leaf routers only). We ignore this as routing is based on the direction from the RP.
Shared Trees have the advantage of requiring the minimum amount of state in each router. This will lower the overall memory requirements for a network that only allows shared trees. The disadvantage of shared trees is that under certain circumstances the paths between the source and receivers might not be the optimal paths - which might introduce some latency in packet delivery. Network designers must consider the placement of the RP when implementing a shared tree only environment.
Multicast Forwarding
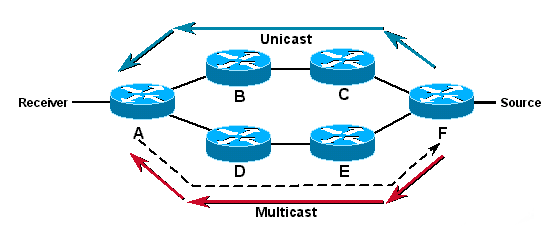
In unicast transmissions traffic is routed through the network along a single path from the source to the destination. A unicast router does not really care about the source address - only the destination and how to forward the traffic towards that destination. The router scans through its routing table and then forwards a single unicast packet out to the correct interface in the direction of the destination.
In multicast routing, the source is sending traffic to an arbitrary group of hosts that are represented by a multicast group address. The multicast router must determine which direction is upstream (towrads the source) and which direction(s) are downstream. If there are multiple downstream paths the router will replicate the packet and forward it down the appropiate downstream paths - which is not necessarily all paths. The concept of forwarding multicast traffic away from the source, rather than to the receiver, is called Reverse Path Forwarding.
Reverse Path Forwarding (RPF)
RPF is a fundermental concept in multicast routing that enables routers to correctly forward multicast traffic down the distribution tree. RPF makes use of the existing unicast routing table to determine the upstream and downstream neighbours, ie to 'orientate' the network and to compute an implicit tree per network source. A router will only forward a multicast packet if it is received on the upstream interface. This RPF check helps to guarantee that the distribution tree will be loop free.
When a multicast packet arrives at a router, the router will perform an RPF check on the packet. If the RPF check is successful, the packet will be forwarded. Otherwise it will be dropped.
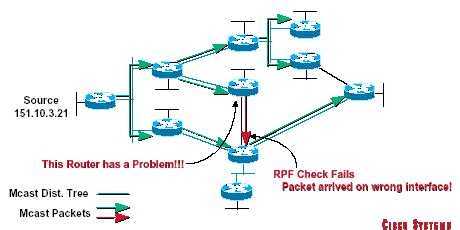
In this example, the router receives multicast data on two interfaces,
On interface 1, it performa RPF Check on the multicast data received on interface E0; RPF Check succeeds as the data was received on specified incoming interface from source 151.10.3.21; data is therefore forwarded through all ougtgoing interfaces on the multicast distribution tree.
On interface 2, E1, the RPF Check fails as the data was not received on the specified incoming interface from source 151.10.3.21 and so the data is silently dropped.
For traffic flowing down a source tree, the RPF check proceedure works as follows,
1. Router looks up the source address in the unicast routing table to
determine if it has arrived on the interface that is on the erverse path
back to the source.
2. If packet has arrived on the interface leading back to the source
the RPF check is successful and the packet will be forwarded.
3. If the RPF check in 2 fails, the packet is dropped.
This is shown below,
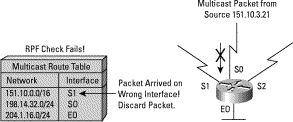
A multicast packet from source 151.10.3.21 is received on interface S0. A check of the unicast route table shows that the interface this router would use to forward unicast data to 151.10.3.21 is S1. Since the packet has arrived on S0 the packet will be discarded.
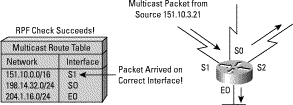
This time the multicast packet has arrived on S1. The router checks the unicast routing table and finds that S1 is the correct interface. The RPF check passes and the packet will be forwarded.
To compute the shortest path, the router looks at the shortest path from the source to the node, rather than from the node to the source. There is then a check to see whether the local router is on the shortest path between a neighbour and the source bfore forwarding a packet to that neighbour. If this is not the case, there is not point in forward a packet that will immediately dropped by the next router. This means that RPF results in a different spanning tree for each source.
This is an example of Reverse Path Forwarding (RPF), where the source floods the network with multicast data. Each router has a designated incoming interface (RPF interface) on whcih multicast data can be received from a given source.
Mode Based Routing
IP Multicast routing protocols generally follow one of two basic approaches, depending on the expected distibution of multicast group members throughout the network. The first approach is based on the assumption that the multicast group members are distributed densley throughout the network (ie many of hte subnets contain at least one group member), and that bandwidth is plentiful. This is called 'Dense Mode' multicast routing and relys on a technique called flooding to propogate information to all network routers.
The second approach is that the mulitcast group members are sparely distrubuted throughout the network and that bandwidth is not necessarily widely available. This is especially true across many regions of the internet or if users are connected via ISDN lines. The term sparse mode does not imply that the multicast has few participating members, but that widely dispersed. In this case, flooding the network would cause unncessary waste network bandwidth and hence could cause serious problems. Sparse Mode therefore must rely on more selective techniques to set up and maintain multicast trees.
Dense Mode Multicast
Distance Vector Multicast Routing Protocol (DVMRP)
The first protocol developed to support multicast routing, it has been widely used on the MBONE. DVMRP constructs a different distrubtion tree for each source and its destination host gorup. Each distribution tree is a niminum spanning tree from the multicast source as the root fo the tree to all multicast recievers as leaves of the tree. The distribution tree procides a hortest path ebtween the source and each multicast receiver in teh group, based on the number of hops in the path, which is tthe DVMRP metric. A tree is constructedd on demand, using a 'broadcast and prune' technique when a source begins to transmit messages to a multicast group.
DVMRP utilises a special RIP-like multicast routing table plus,
| Poison-Reverse | A special metric of Infinity (32) plus the original received metric, used to signal that the router should be plcae on the distribution tree of the source network. |
| Prune and Grafts | Routers send Prunes and Grafts up the distribution similar to PIM-DM |
In this description we shall assume that all routers on the network support DVMRP. This simplifies the description. DVMRP assumes that initially every host on the network is part of the multicast group. The designated router on the source subnet, ie the router tha has been slected to handle routing for all the hosts on its subnet, begins by tranmitting a multicast message to all adjacent routers, each of which then selectively forward the message to downstream routers, until the message eventually passses to all multicast group members.
The selective forwarding during the formation fo the spanning tree works as follows: When a router receives a multicast messages, it checks its unicast routing tables to detemrine the interface that provides the shortest path back to the source. If that was the interface over which the multicast message arrived, then the router enters some state information to identify the multicast gorup in its internal tables (specifying infterfaces over which the message for that group should be forwarded) and forwards the multicast message to all adjacent routers, other than the one that sent that message. Otherwise, the message is simply discarded. This mechanism, called Reverse Path Forwarding, ensures that there will be no loops in the tree and that the reee will included shortest paths from the source to all receipents. This basically the broadcast part of the protocol.
DVMRP actually uses a forwarding process that is even more selective than that described above. By relying on specific information that is provided by the unicast routing protocol. This implies that DVMRP must contain its own integrated unicast routing protocol. A DVMRP router, say MR1, contains information in its unicast routing tables that enables it to determine if an adjacent router, say router MR2, will recognise MR1 as being the shortest path back to the multicast source. This enables MR1 to forward a multicast message to MR2 only if MR2 will be able to use it to further the construction of the multicast tree. This enhancement results in a considerable reduction in the number of flooing messages that are required to construct the distribution tree.
The prune part of the protocol eliminates branches of the tree that do not lead to any multicast group members. The IGMP, running between hosts and their immediately neighbouring multicast routers, is used to maintain group-membership data in the routers. When a router determines that no hosts beyond it belongs to the multicast group, it sends a prune message to its upstream router. Routers must update (source, destination group) state information in their tables to reflect which branches have been pruned from the tree. This process continues until all superfluous branches are elimated from the tree, resulting in a minimum spanning tree.
Construction of such a tree is shown below.
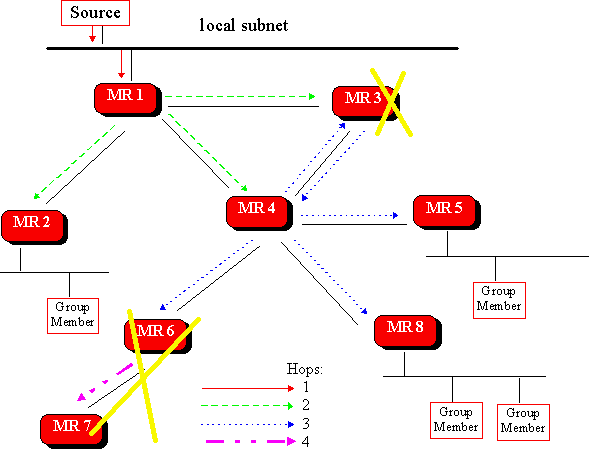
Once the spanning tree is constructed, it is used to transmit multicast messages from the source to the multicast members. Each router in the path forwards messages over only those interfaces that leads to group group members. Since new members may join the group at any time, and since these new member may depend on one of the pruned branches to receive the multicast transmission, DVMRP periodically reinitiates the construction of the spanning tree.
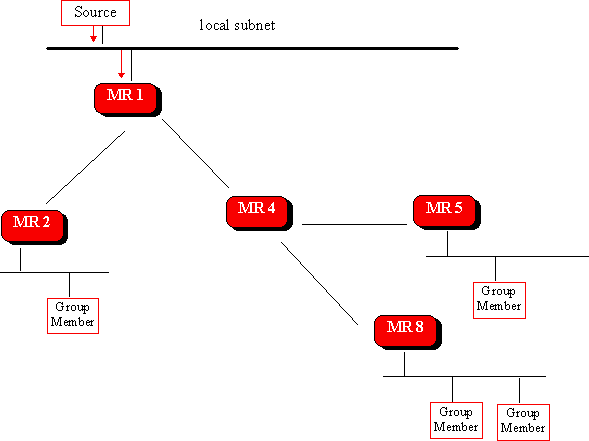
DVMRP works well for multicast groups that are densely represented within a subnet. However, for multicast groups that are sparesely represneted over a wide-area network, the periodic broadcast behaviour would cause serious performance problems. Another problem with DVMRP is the amount of multicast routing state information that must be stored in the multicast routers. All the mulicast routers must contain state information for every (source, gourp) pair, eitehr information designating the interface to be used for forwarding multicast messages or prune-state information. For these reason, DVMRP does not scale to support multicast groups that are distributed over a large network.
For more information, click here.
Multicast Open Shortest Path First (MOSPF)
Open Shortest Path First (OSPF) is a unicast routing protocol that routes messages along least-cost paths, which the cost is expressed in terms of a link-state metric. In addition to the number of hops in a path, other network performace parameters that can influence the assignment of cost to a path include load-balancing information (eg a link that has very little traffic might be assigned a lower cost than a heavily utilised link, in an attempt to balance traffic on the network), an application's desired Quality of Service (eg if an application requires low latency, a path involving a satellite link should be assigned a high cost), etc.
MOSPF is intended for use within a single routing domain, for example, a network controlled by a single organisation. It is dependent on the use of OSFP as the accompaning unicast routing protocol, just as DVMRP includes its own unicast protocol. In an OSPF/MOSPF network, each router maintains an up-to-date image of the topolgy of the entire network. This 'link-state' information is then used to construct multicast distribution trees.
Each MOSPF router peridocially collects information about multicast group membership via IGMP. This information, alond with the above link-state information is flooded to all other routers in the routing domain. Routers will update their internal link-state information based on information that they receive from adjacent routers. EAch router, since it understands the topology of the network, can then independently calculate a least-cost spannign tree with the multicast source as the root and the group members as leaves. This tree is the path that is used to route mulicast traffic from the source to each of the group members. Note that all routers will calculate exactly the same tree, since they peridocally share link-state information. HOwever, MOSPF does not scale well due to the periodic flooding of link state information amongth the routers.
MOSPF uses the Dijkstra algorithm to compute the shortest-path tree. A separate calculation is required for each (source, group) pair. To reduce the number of calculations tand to spread the calculations somewhat, a router only makes this calculation when it receives the first datagram in a stream. Once the tree is calculated, the information is stored for use in routing later datagrams from that stream. This is shown below,
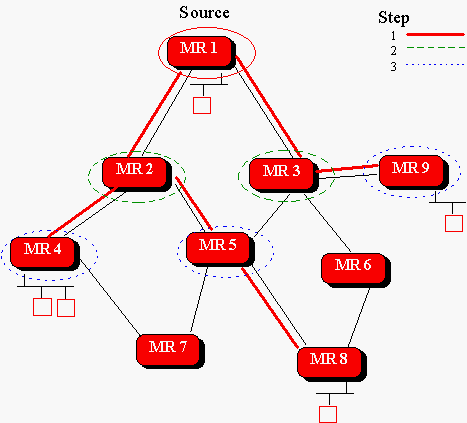
Click here for more information.
Sparse-Mode Multicast
Whilst Dense-Mode multicast relies on a flooding the network of messages can prove efficient on LAN networks, consider the implications if several multicast sessions across the internet. The aggregate traffic from this periodic flodding could potentially saturate the wide-area-network.
Dense-Mode replies on protocols that use a data-driven approach to construct multicast distribution trees. Spare-Mode protocols rely on a receiver-initiated process, ie a router becomes involved in the construction of a multicast distribution tree only when one of the hosts on its subnet requests membership in a particular multicast group.
Core Based Trees (CBT)
Some multicast applications, such as distributed interactive simulation and distributed vide-gaming, have many active senders within a single multicast group. Unlike DVMRP or MOSPF, which construct a shortest-path tree for each (source, group pair), the CBT protocol constructs a sinlge tree that is shared by all members of the gourp. Multicast traffic for the entire group is send and received over the same tree, regardless of the source. This use of a shared tree can provide significant savings in terms of the amount of multicast state information that is stored in individual routers.
CBT utilises the underlying unicast routing table plus the Join/Prune/Graft mechansims like those implemented in PIM-SM.
A CBT shared tree has a core router that is used to construct the tree. The process is shown below.
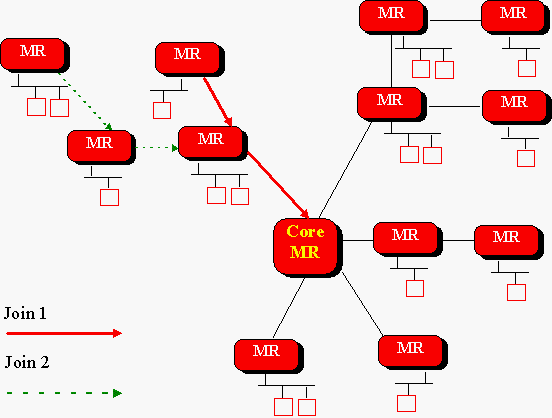
Routers join the tree by sending a join message to the core. When the core recieves a join request, it returns an acknowledgement over the reverse path, this forming a branch of the tree. Join messages need not travel all the way to the core before being acknowledged. If a join message hits a router on the tree before it reaches the core, that on-tree router terminates the join and acknowledges it. The router that sent the join is then connected to the shared tree.
CBT aggregates traffic onto a smaller subset of links than would be used for source-based trees. The resulting concentration of traffic around the core is a potential problem for this approach. Some versions of CBT support the use of multiple cores; load balancing might be achieved through the use of more than one core.
See here for more information.
Protocol Independent Multicast (PIM)
PIM is a protocol developed with the objective to standarise multicast routing that can provide a scalable interdomain routing across the internet, independent of the mechanisms provided by any particular unicast routing protocol. As such, it has two operational modes, one for densely distributed multicast groups and one for sparsely distributed groups.
PIM can leverage whichever unicast routing protocols are used to populate the unicast routing table, including EIGRP, OSPF, BGP or static routes. PIM uses unicast routing information to perform the multicast forwarding function, therefore it is IP protocol independent. Although PIM is called a multicast routing protocol it actually uses the unicast routing table to perform the RPR check function instead of building up a completely unrelatedmulticast routing table. PIM does not send and receive multicast routing updates between routers like other routing protocols.
PIM utilises the underlying unicast routing table plus,
| Join | Routers add their interfaces and/or send PIM-JOIN messages upstream to establish themselves as branches of the tree when they have interested receivers attatched. |
| Prune | Routers prune their interfaces and/or send PIM-PRUNE message upstream to remove themselves from the distribution tree when they no longer have interested receivers attatched. |
| Graft | Routers send PIM-GRAFT messages upstream when they have a pruned interface and have already send PIM-PRUNE's upstream, but receive an IGMP host report for the group that was pruned; routers must reestablish themselves as branches of the distribution tree for the source network. |
Protocol Independent Multicast - Dense Mode (PIM-DM)
PIM-DM is similar to DVMRP. Both protocols employ Reverse Path Multicasting (RPM) to construct a source-rooted distribution tree. The major differences are that PIM is completely independent of the unicast routing protocol that is used on the network. DVMRP relies on specific mechanisms of the associated unicast routing protocol. Also PIM is less complex than DVMRP.
PIM-DM is data driven, like all dense mode protocols. However, since it is independent of the accompanying unicast routing protocol, data packets which arrive at a router over the proper receiving interface (ie the interface that provides the shortest path back to the source), are forwarded on all downstream interfaces until unnecessary branches of the tree are explicitly pruned. Recall that DVMRP can be more selective when it forwards messages during the tree construction phase by using more specific topology information provided by its own unicast rouing protocol. The philosophy followed by PIM-DM designers is to opt for protocol simplicity and protocol independence, even though there is likely to be additional overhead due to some packet duplication.
The process of initial flooding (push) repeats every three minutes. PIM-DM can only support source trees (S,G) entries. It cannot build shared distribution trees.
Click here for an example.
Protocol Independent Multicast - Sparse Mode (PIM-SM)
Similar to CBT, PIM-SM is designed to restrict multicast traffic onlyh to those routers interested in receiving it. PIM-SM constructs a multicast distribution tree around a router called the redezvous point (RP). This RP plays the same role as the core in the CBT protocol; recievers 'meet' new sources at this RP. However, PIM-SM is more flexible than CBT as under PIM-SM an individual receiver may choose to construct either a group shared tree of a shortest path tree. CBT trees are always group-shared trees.
The advantage to shared trees is that it is relatively easy to construct, and it reduces the amount of state information that must be stored in the routers. Accordingly, a shared tree would conserve network resources if the multicast group consisted of a large number of low-data-rate sources. However, as indicated above, shared trees cause a concentration of traffic around the core or the RP. A phenomenon that can result in performance degradation if there is a large volume of multicast traffic. Another disadvantage is that with shared trees, traffic does not traverse the shortest path from source to destination. If low latency is critical, it would be preferable for traffic to be routed along the shortest route. As PIM-SM supports both types of tree, it has a major advantage.
PIM-SM initially constructs a group-shared tree to support a mulicast group. The tree is formed by the senders and receivers both connected to the RP, just as a shared tree is constructed aruond the core under the CBT protocol. After the tree is constructed, a receiver (actually the router closest to the receiver) can opt to change its connection to ta particular source to a shortest-path tree. This is done by having this router sends a PIM join message to the source. Once the shortest path from source to reciever is created, the extraneous branches through the RP are pruned. Different types of tree can be selected for difference sources within a single multicast group. The construction of the tree is shown below.
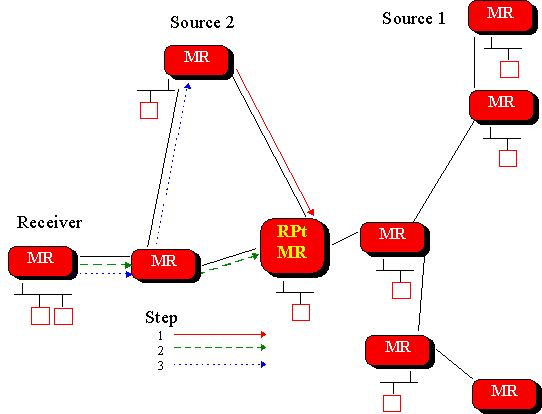
PIM specifies soft-state mechanisms to periodically refresh system state, adapt to topolical changes in the network, and adapt to changes in group membership. While PIM relies on unicast routing tables to adapt to network topology changes, it is independent of the particular unicast routing protocol that is needed to construct these tables. Other features of PIM, such as using multiple RPs to elimate the probelm of having single failure point, can be found here.
Click here for an example of PIM-SM construction.
Sparse-Dense Mode
Cisco has implemented an alternative to just choosing sparse mode on a router interface. This was necessitated by a change in the paradigm for forwarding multicast traffic via PIM that became apparent during its development. It turned out that it was more efficient to choose sparse or dense on a per group basis rather than a per router interface basis. Sparse-Dense Mode facilitates this ability.
Interoperability
There are two broad types of interoperability considerations,
·
Interoperability between existing unicast and emerging multicast-capable
routers.
· Interoperability between the various approches to multicast routing.
An example of the first consideration is that DVMRP is currently used for multicast routing on the MBONE. A method of tunnelling is used to connect multicast capable islands within the internet. In addition, MOSPF was designed on top of ODPF version2 so that a multicast routing capabilty can be introduced into an OSPF version routing domain.
PIM has to consider the second consideration. It has to enable interoperability between PIM-DM and PIM-SM, and also to enable interoperability between PIM and other multicast routing architectures. If a Dense-Mode group is to interoperate with a sparse mode group, eg to form a gorup that is sparely distruted over a WAN but is densely distributed within a single subnet, ther emust be a mechanism for allowing the dense group to reach out to the sparse group to request a join. The solution propose by PIM is to have 'border' routers send explicit joins to the sparse group. Note that the same approach would enable PIM-SM to interoperate with other dense-mode protocols.
Links
RFC 1075 - DVMRP
IETF Draft - Distance Vector Multicast Routing Protocol Update
RFC 1584 - Multicast extensions to OSPF
IETF Draft - Core Based Trees (CBT) Multicast Protocol Specification
Protocol Independent Multicast-Dense Mode (PIM-DM): Protocol Specification
Protocol Independent Multicast-Sparse Mode (PIM-SM): Protocol Specification
Protocol Independent Multicast-Sparse Mode (PIM-SM): Motivation and Architecture
IETF Draft - Interoperatibilty Rules for Multicast Routing Protocols
| Sun, 21 October, 2001 19:34 |
Room D14, High Energy Particle Physics, Dept. of Physics & Astronomy, UCL, Gower St, London, WC1E 6BT