

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Socket Buffer Tests
This is an investigation into the effect of socket buffer sizes on transfer rates.
<1st year report>
The problem statement is that the effect of socket buffer should not affect tcp transfer rates past some threshold which is approximately the bandwidth delay product. This investigation is based on back to back GigE transfers and WAN transfers.
Setup
Scripts: scripts used are
do_socketbuffer.pl - a script to wrap around iperf
graph.pl - a graphing script to poll results
All tests will be run with iperf 1.6.1 with a duration of 10 seconds with the server on pc56 with socket buffers 8192k. Runs 1 to 8 were conducted on 24 une 2002.
NOTE: the socket buffer sizes stated are incorrect and the actual value is twice that shown on the x axis!
Run 1
The bandwidth delay product of tcp transfers between pc55 and pc56 is about 18k socket buffer. Run 1 will give investigate into acceptable ranges that socket buffers should be set at for LAN measurements. The tests will include socket buffer sizes of {2,5,10,15,20,25,30,35,40,50,60,70,80}k
results here.
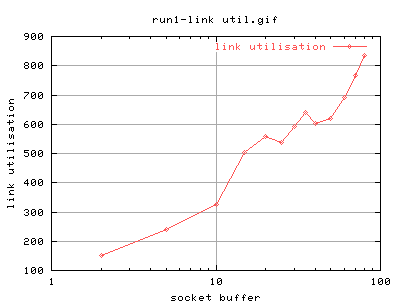
Hmm... seems like the bandwidth delay product isn't very good is it? ping still gives an average of about 150usecs = 0.150ms = 150e-6. 1Gb/sec = 1,000,000,000bits/sec. Bandwidth*delay gives socket buffersize; 1e9*150e-6 = 150,000 bits = 18.3kbytes... hmmmm
Lets try larger buffer sizes then (interesting thing to note is that we're nearing 900mbytes/sec!
Run 2
Lets see how far this trend goes.... we're gonna do {100,200,300,400,500,600,700,800,900,1000}k
results here.
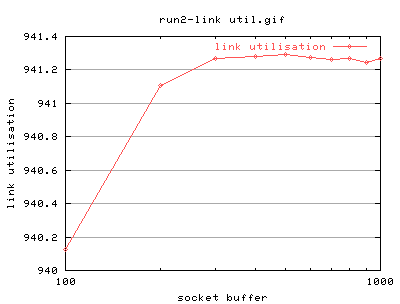
Hmm... at least it's tending off! Right, so we get a max of 941mbytes/sec - not bad! This starts plateuing at about 300k. A heck of a lot more than that defined in the bandwidth delay product. But to be fair, i don't think that the bandwidth delay product was supposed to be used at such a low delay.
Think we need to test using udpmon as well to see how this collorates.
So lets' refine it for test 3
run 3
From run 1 and 2, the following socket buffers are chosen. We should go a lot higher to see if the affects on the WAN can be seen here. So we'll go about 10 bigger than the optimal socket buffer size.
{2,5,15,25,50,100,125,150,175,200,225,250,275,300,325,350,375,400,500,600,700,800,900,1000,1250,1500,1750,2000,3000,4000}k
A bit long, but it should give a good graph! :) and as i'm not running on the WAN, i'm not hurting anyone! :)
results here.
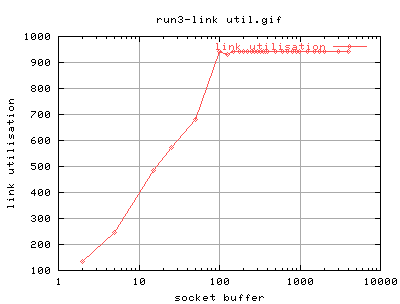
Hmm... opps! missed it. at least we know that there's not much point doing runs above 250k. But hold, on, the start of the plateau seems to have moved... ?
run 4
So lets do a lot more between 10 and 100...
{2,5,8,10,15k,20k,25k,30k,35k,40k,50k,60k,70k,80k,90k,100k,105k,110k,115k,120k,125k,130k,140k,150k,160k,170k,180k,190k,200k,210k,220k,230k,240k,250k}
results here.
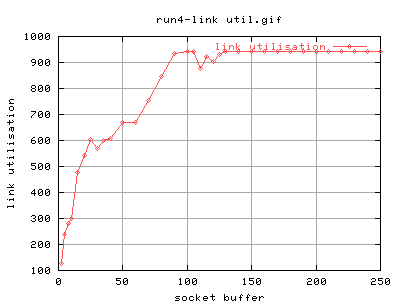
Not very smooth is it? Think we should try it again. Don't think we need to bother with tests over 150k. (what happened to 300 eh?)
Run 5
resutls here.
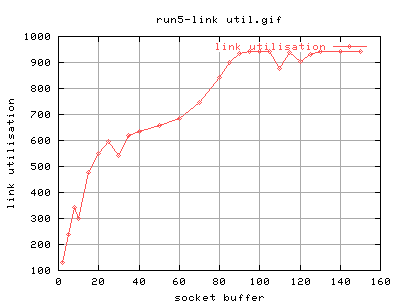
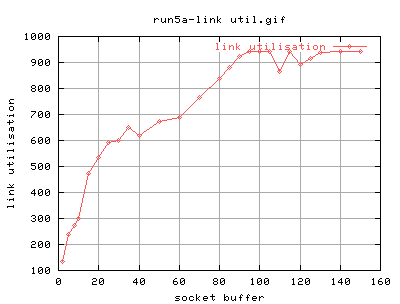
It's certainly better... Now the start of the plateu seems to be at about 90k. There's still that funny dip at about 110k tho.
There also seems to be two regions of plateau - between 20k-60k and the bit after 90k. The question is where this first plateau comes from. At first guess, i would say that it might have something to do with the autotuning tcp buffers on the 2.4 kernels. They are currently set to a default of 64k. The real question is how this interfers with the socket buffers specified by iperf.
There also seem to be glitches 8k, 30k and 35k. The rest of it seems pretty constant. These could be attributed to rounding errors as they are quite near the 8k and 32k. So may be autotuning buffers on the 2.4 kernels are a little iffy? dunno.
Anyway, let's investigat the funny glitch at 110k.
Run 6
Investigate glitch in range 100k to 140k. socket buffers: {100k, 105k, 110k, 115k, 120k, 125k, 130k, 135k, 140k}
results here.
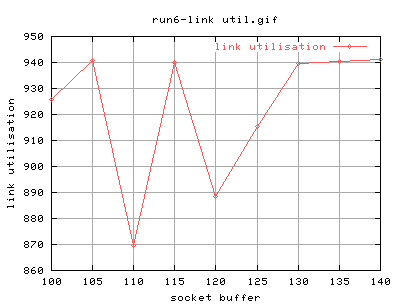
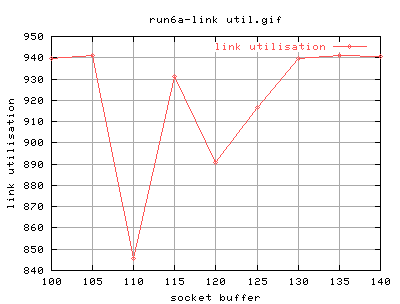
There appears to be abrupt changes in link_utilisation at 110k and 115k. The values for the other points seems quite constant. I think we need finer steps.
Another question is where the start of the plateu actually is. Is is at 90k or is it actually at 130k? Let also start using 2^* values rather than multiples of 5.
Run 7
results here.
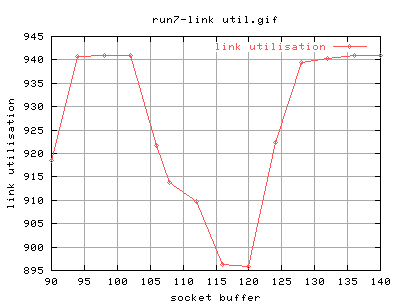
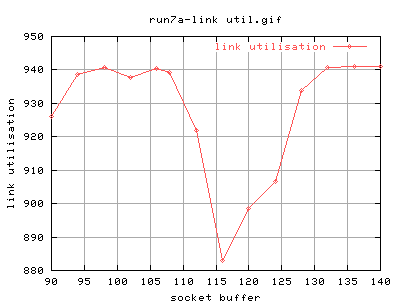
Well, it's not as consistent as i thought... any thoughts?
Certainly, as a threshold, i would rather say that 132k is the optimal socket buffer size for back to back connection as any higher values do not give a change in link_utilisation.
run 8
Okay, so we have the region where there's a plateau; to make use of this, lets look at the web100 result when we are bounded by our socket buffers (the linear bit), at a region where we are beginning to plateau off (the steading off) and a region where we are wholly limited (the plateu).
Web100 traps were set to the minimum allowable by kernel space - 10ms.
socket buffers {20k, 82k, 140k} - results here.
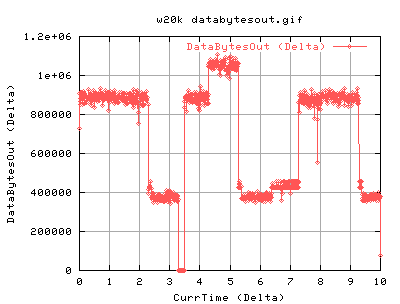
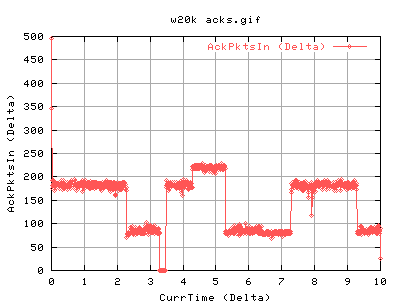
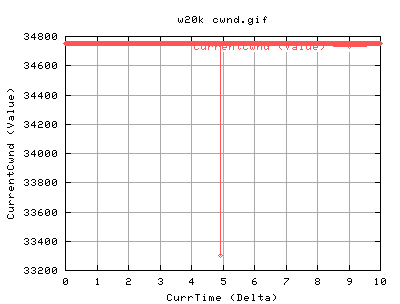
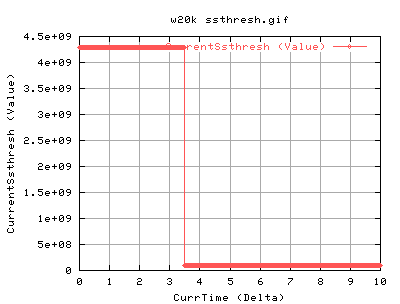
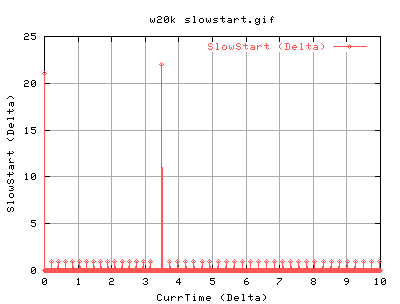
For 20k socket buffer:
 |
 |
 |
 |
 |
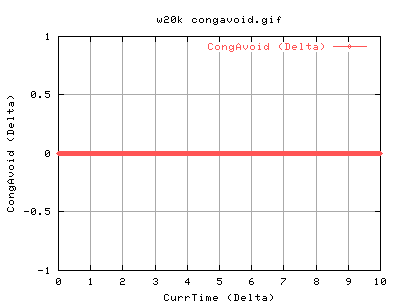 |
One can see that the dataoutput is quite bursty - there's periods of high throughput and then low throughput. This is proportional to the number of ACKS coming in )approx). There is a period of inactivity at just after 3 seconds which is most likely due to a lost packet.
The information from the cwnd and ssthresh are pretty useless to be honest. With the update of ssthresh only occuring as a result of the lost packet. However, the connection is experiencing some network feedback as it has to continuously go into slowstart, almost periodoically. The strange thing is that it never seems to go into congestion avoidance... strange....
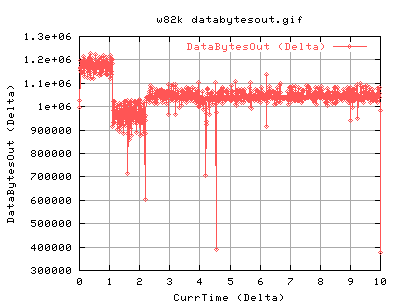
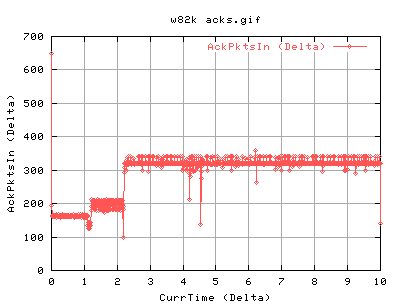
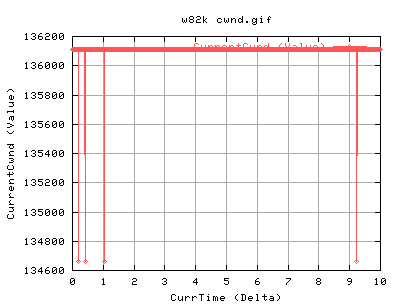
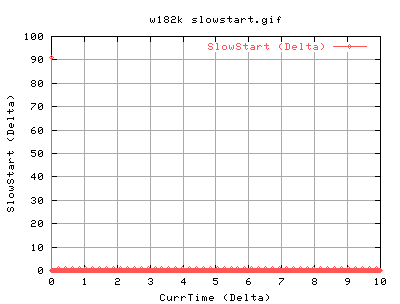
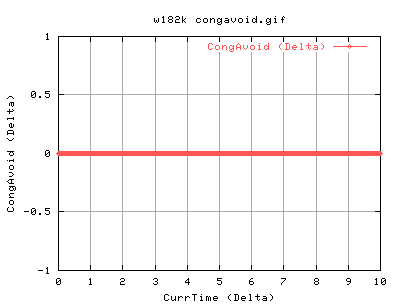
For 82k:
 |
 |
 |
 |
 |
 |
One can see that the overall databytesout is greater than in the 20k case. There is also less flucuations in the values. Again, the cwnd and ssthresh aren't that helpful, but the slow start graph shows that it does a lot of slow start intially - good as it probes the network. It then continues with it's periodic slow start, about 5 times every second.
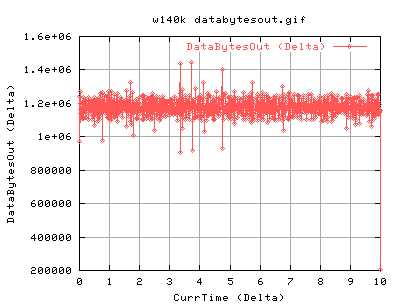
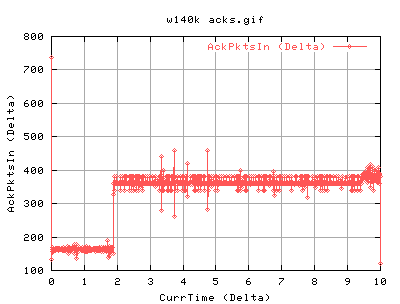
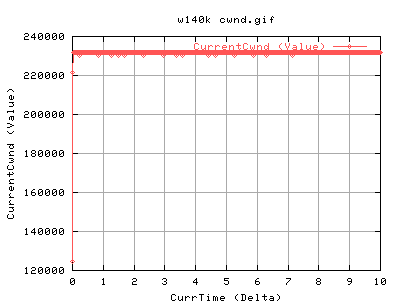
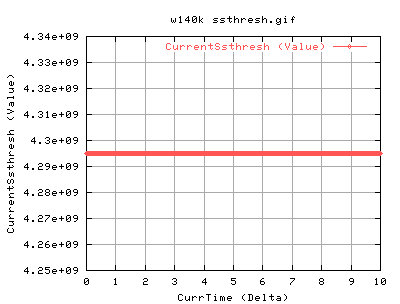
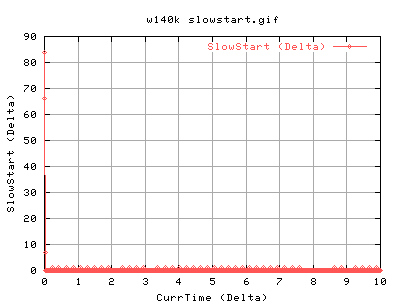
For 140k:
 |
 |
 |
 |
 |
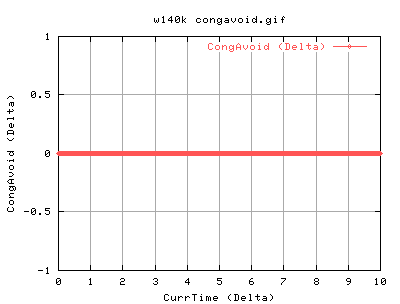 |
140k shows very similar results to the 82k case. There is slightly more acks coming back as we are sending out more. Again the it spends a lot of time in slow start at the beginning of the conneciton. Does CongAvoid work??? Surely, the tcp should do into congavoidance - however, as ssthresh is always 4gb, cwnd never gets a chance to go anywhere near it, and hence the tcp connection is always in slow start. However, congestion signals from the network should always update the cwnd, and ssthresh. Congestion signals are either timeouts or duplicate acknowledgements. So this tcp is correct in not updating it's value of ssthresh.
Is the effect of socket buffer sizes only inherient in the amount of data send out into the network? Yes... so is there anyway of determining from the reciever end whether we are at the optimal socket buffer size? If the reciever did not have enough reciever buffer, then we would see looses at this end, causing congestion signals and updates of ssthresh and cwnd.
A item to think of is that the rtt is about 150usecs. Considering the highest resolution of web100 traps is 10ms (probably due to kernel parameters), then we get about 90-odd rtts per trap. On a longer latency link, eg, UCL to Manchester, we should get approximately one rtt per trap, and hence giving a much better indication of the evolution of Cwnd and SSthresh.
I think it's not much use to look at LAN tests for tcp traffic. There's not enough loss!
Look at dupacks, different types of packets out.
| Tue, 9 July, 2002 1:15 |
Room D14, High Energy Particle Physics, Dept. of Physics & Astronomy, UCL, Gower St, London, WC1E 6BT