

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Investigation into the effects of Autotuned buffers on throughput and bandwidth delay product
AIM: To find a relation between the autotune tcp settings of the 2.4 kernels, values located in /proc/sys/net/ipv4 and the affects of reduced/increased throughput with the evolution of a tcp connection performing BTC (with iperf).
Setup
This is to be conducted on a back to back system at GigE rates. The pcs are pc55 and pc56 with modified 2.4.16 kernels for web100 monitoring. These tests were conducted on 27th June 2002.
Scripts used are:
do_socketbuffer.pl, graph.pl (now supports multiple y axis), logvars
Method
For varying values of default socket buffer, as set in the /proc/, perform a series of measurements of throughput for varying socket buffer sizes as set with iperf. The values of the default socket buffer size are to range from 8k to 136k as these values determine minimal useable values and the found optimal socket buffer size for the connection (at least with a 16k kernel default). The socket buffer sizes to be investigated and varied with iperf are to be: {4, 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48, 52, 56, 60, 64, 68, 72, 76, 80, 84, 88, 92, 96, 100, 104, 108, 112, 116, 120, 124, 128, 132, 136, 140}k
All tests are performed between pc55 and pc56 on a back to back configuration on a gigE link (crossover).
The kernel parameters were set by echoing the values into /proc/sys/net/ipv4/tcp_wmem on pc55 (from which iperf transfers are conducted from). These were set to 4k mimimum and 8m max. The recieving machine (pc56) was set with /proc/sys/net/ipv4/tcp_rmem as (4096 131072 8388608) implying a min of 4k, default of 128k and max of 8m.
All transfers were conducted for 10 seconds and web100 traps were set at every 10ms.
Run 1 - 8k
Run at 8k.
Note - using web100, it was found that the specified window size in iperf is actually twice that of the set value. eg if a 32k socket buffer size is set in iperf, then the actual value of the connection is actually 64k.... dammit! I will continue the tests with the same script (ie the socket buffer is shown in the following graphs are actually twice the value shown for the iperf graphs). The values set in the kernel are still correct, however. :)
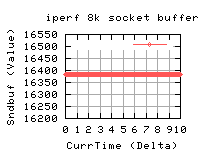


These graphs show that for various socket buffer sizes set in iperf, the actual values, as reported by tcp and web100 are that it's twice that set in iperf.
So if i run iperf -w 64k, the actual value used is 128k - as it reports in it's header.



As you can see the rcv buffers are also the same as the send buffers.
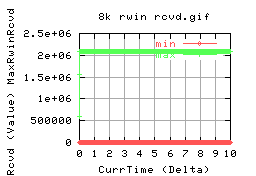


Yeah, not very interesting, except the min rwin rcvd is always 8672bytes, and the max is always 2096704 (2megs). This is strange, as the iperf server on pc56 is set to 8megs through iperf... the iperf server reports that the actual window has been set to 16Mbytes... wrong again! This could also account for the problems with the WAN tests - with increasing socket buffer size, the performance decreases. The actual value of this seems to be at what iperf calls 1024k - which is actually 2048k for the sender socket buffer. This stream has to go to the iperf server. In this test, the server was set to have 8megs of reciever socket buffer. However, the above graphs show that it actually only achieves 2megs. This value is the same as that of the optimal socket buffer size for the highest bandwidth.
The question is how does tcp handle this? TCP should only send the minimum of the reciever advertised window (rwin) and cwnd. The cwnd grows according to acks. It will only ever send out the number of bytes that is min(rwin, cwnd). So if our socket buffer size is greater than 2megs, why does throughput decrease? (on a WAN anyway)... hmm i'll think about it.
run1 - trends
















Ignoring the two graphs that look funny (i'll do them again in a mo to check).
Remembering that the x axis is actual half the real value... we see... err no trend! Looking more closely tho', there is a small noticable thing: considering that the actual socket buffer set by iperf is half the x value, then the region before the value that matches the setting for the kernel socket buffer size is relatively smooth, then just after the value (ie the graph title/2) there is a dip in performance. This is most likely because of the fact the 2.4 kernels have to reallocate memory to accomodate the extra requirement in socket buffer sizes - perhaps badly, hence reduing the performance of the protocol stack.
Just to ensure that hte 48k and the 56k aren't bugs, here's them again,


Script Modifications
do_socketbuffers.pl set to accept the 'real' socket buffer size values - values are halved and supplied to the command line. The logging used by cook.pl is also incorrect as it assumed that the value presented was incorrect. This is not the case. It used to halve the recorded tcp value in the logs, which gives the wrong value. Instead, it now just takes the raw value from the TCP window size: (\d+) line.
Note that GridNM needs to be adjusted also. Similarly, the log files need to be altered. Done.
| Tue, 9 July, 2002 13:02 |
Room D14, High Energy Particle Physics, Dept. of Physics & Astronomy, UCL, Gower St, London, WC1E 6BT