

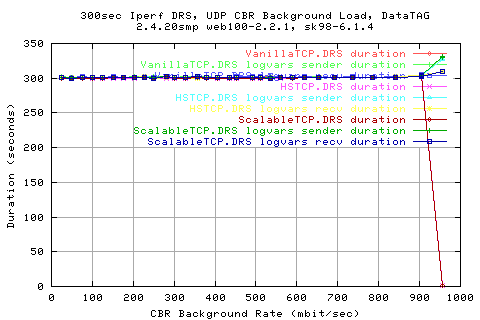
Single TCP Stream CBR Background on DataTAG
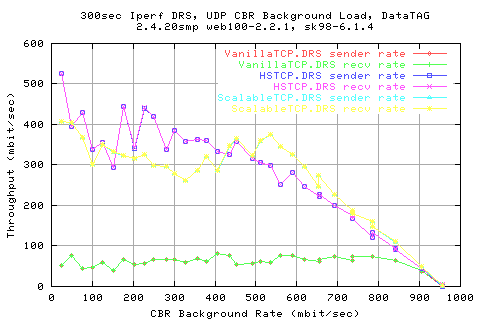
Looking at the throughput graphs, we see that all the stacks perform quite miserably; even the new stacks only manage about 500mbit/sec when there is only 25mbit/sec background load.
Note these tests were performed on a less than perfect configuration of the datatag network; for some reason, packet drops and multiple streams appeared to have problems. TBC.
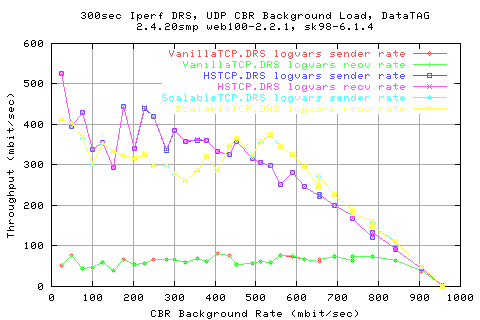
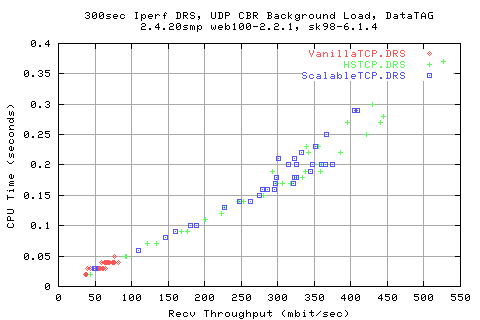
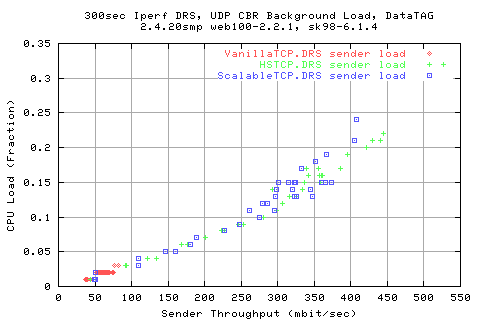
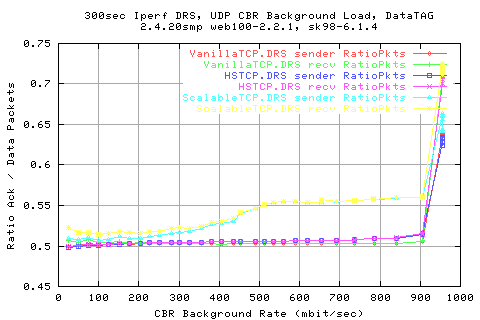
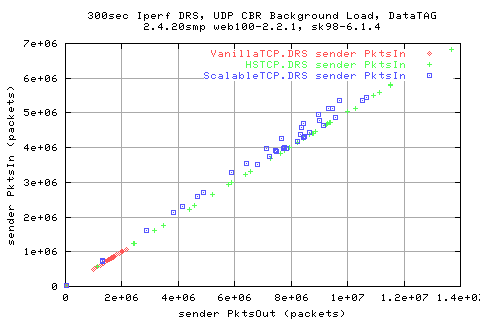
Looking at tet rates at which the recv got the data shows that they are the same as the sender side (unsurprisingly). However, we get far from 100% utilisaiton of the link.
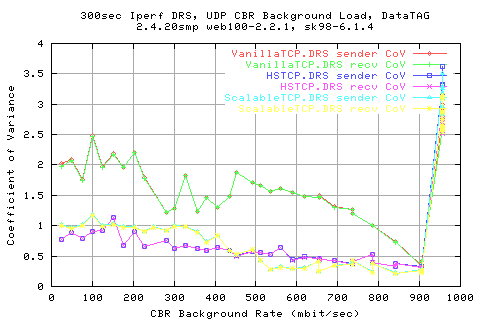
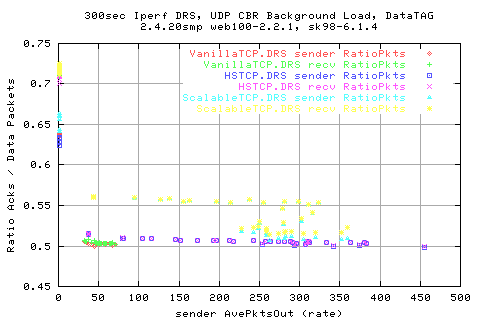
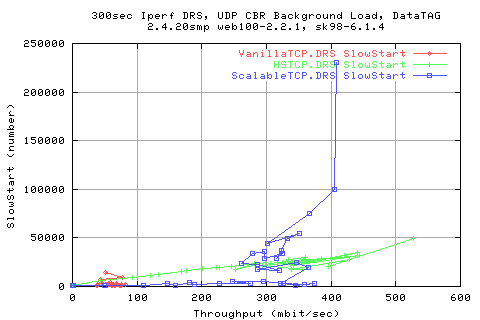
Looking at the CoV shows that we appear to perform almost two times better with the new stacks than with VanillaTCP. We also see that HSTCP performs better at low background rates, with a lower CoV than scalable. However, ScalableTCP performes marginarlly better at the higher throughputs.
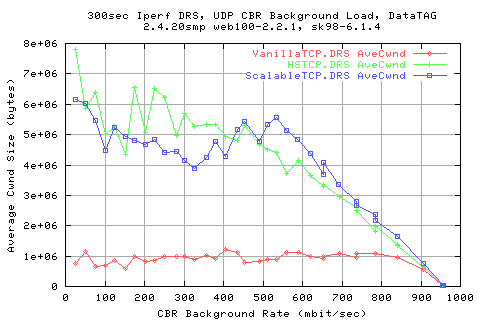
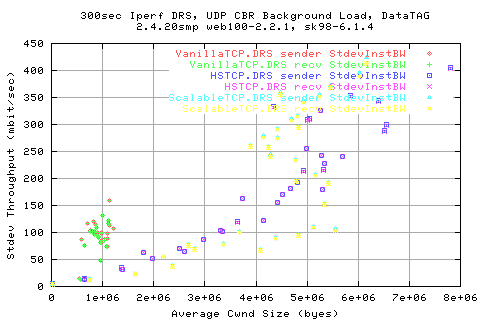
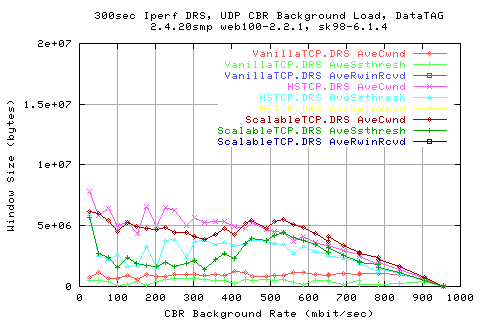
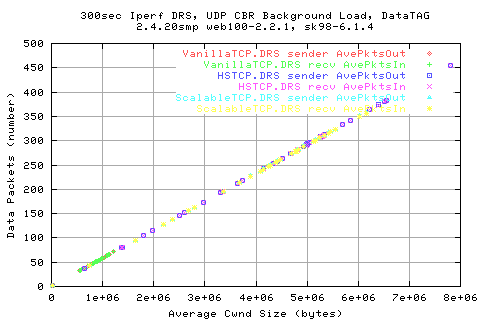
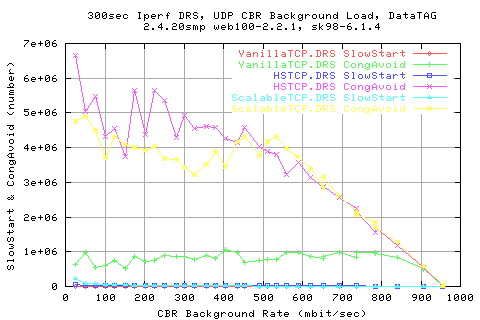
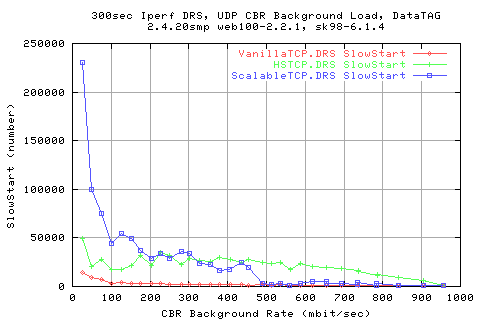
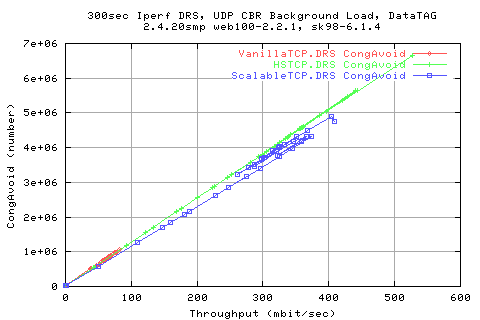
Looking mroe in depth into the protocol, we see that the throughputs are related to the AveCwnd values; HSTCP manages to achieve a slightly higher cwnd than ScalableTCP for low background rates, and vice versa.
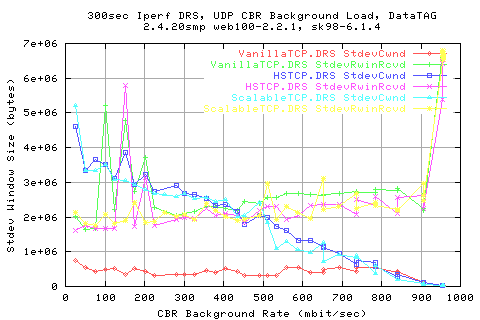
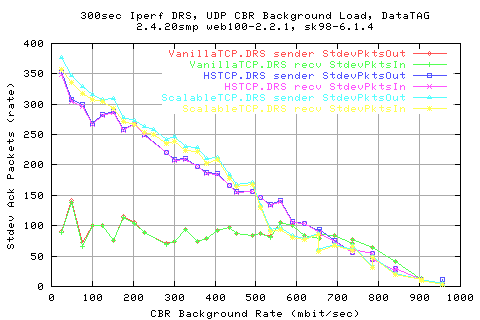
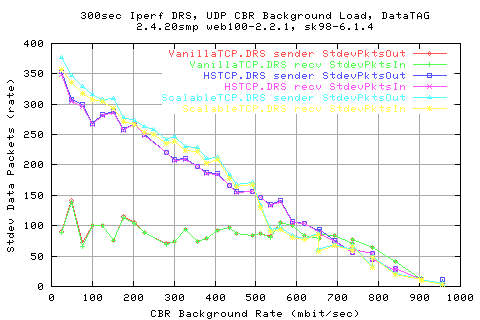
Comparing the stdev of the cwnds shows that HSTCP and Scalable (Darklight blue and light blue resp.) show similar variations in the cwnd change.
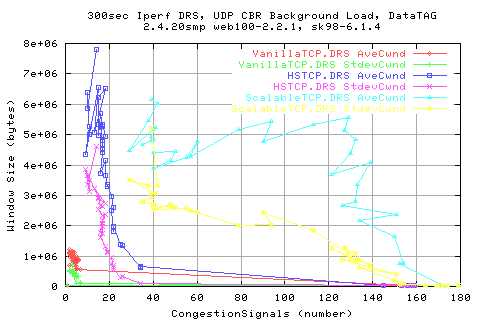
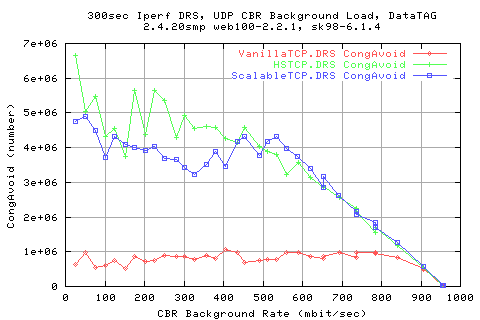
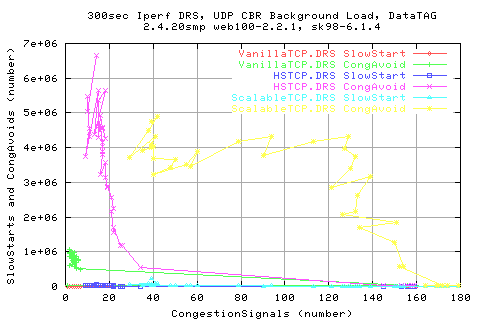
Correlating the window sizes and the number of congestion signals shows that there is a vague relation between the number of congestion signals reducing the window size ( as it should). Looking at the stdev of the cwnd shows that there is less dependence of the stdev of cwnd to the number of congestionsignals.
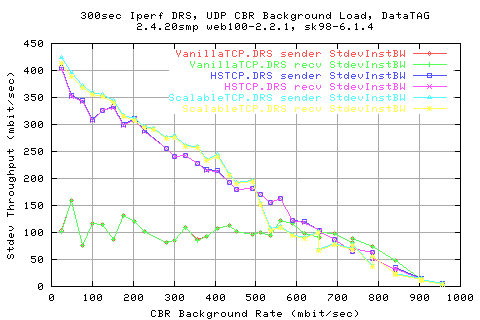
We see that this variation in the cwnd is closely resembled by the variation in the BW......
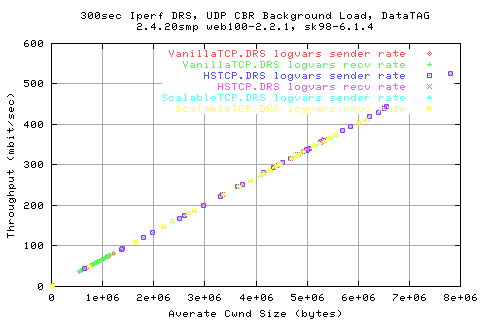
And that there isa direct relation between the two.
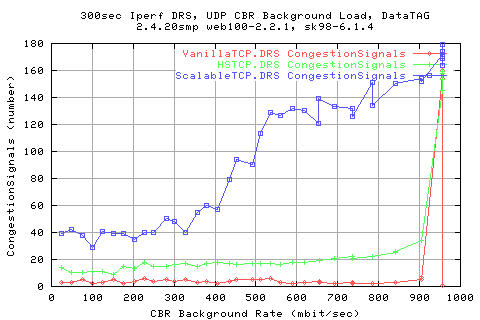
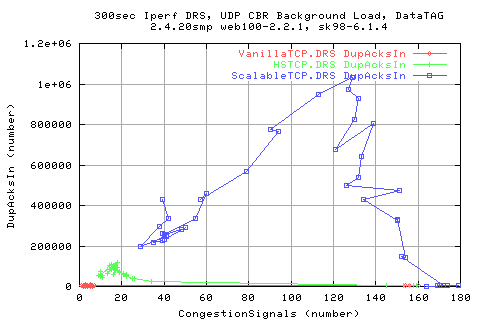
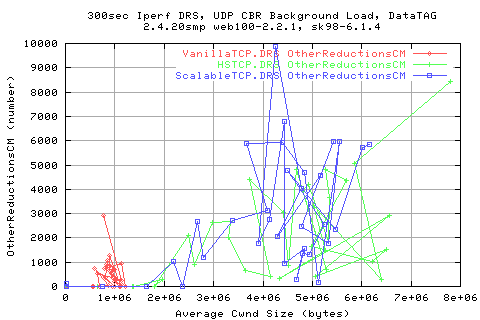
Surprisingly, we see that the numbe of congestion signals for ScalableTCP is much higher than for for the other two protocols. This suggeststs that it must be pushing onto the traffic a lot harder than with the other protocols - assuming that the background traffic is the same for each case.
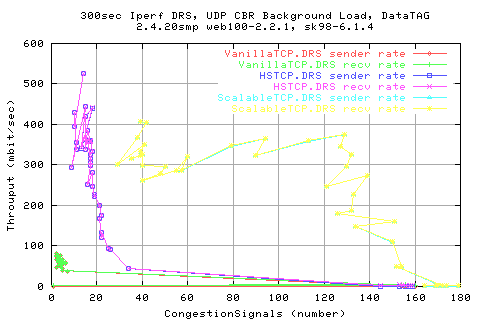
A scatter of throughput ot the congestion signal number shows taht there is a decrease in throughput as we get more congestion signals (as expected). However,m this relation is less for the ScalbleTCP stack - in fact, it appears almost independent.
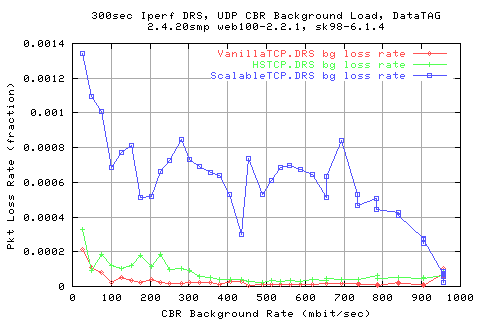
Looking into the loss rates of the cbr background load (number of packets lost, as a fraction of the total number of pkts sent), shows that we do indeed 'push' harder onto the network, creating very high losses for the cbr traffic.
![]()
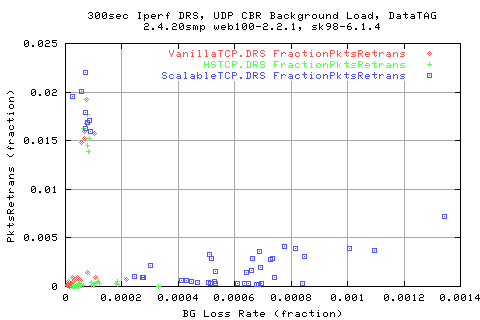
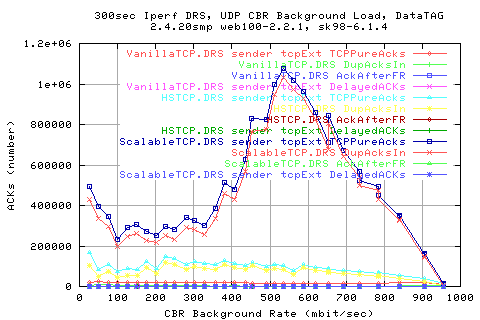
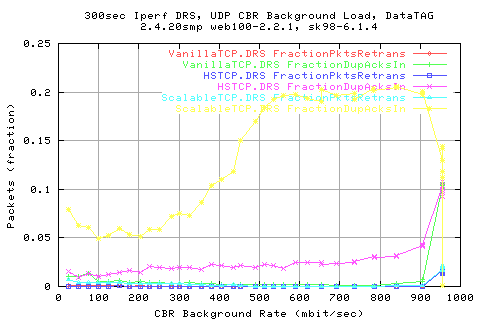
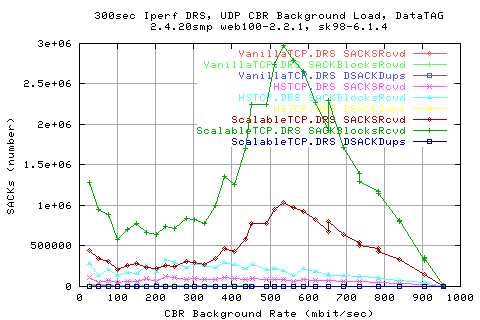
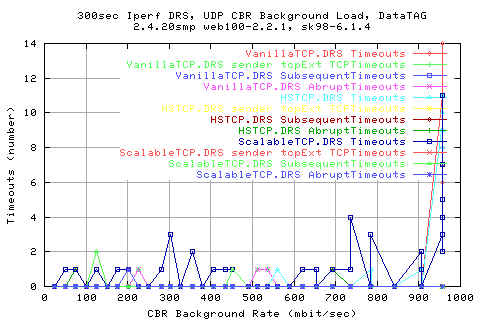
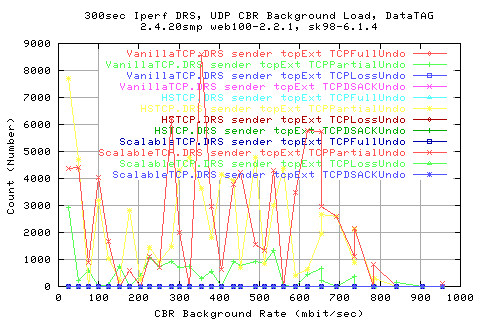
Looking at the number of pkts retransmitted shows that we do indeed have to retransmit alot more packets in Scalable than the other protocols. In fact, by this metric, we see that HSTCP is actually a lot better than VanillaTCP as it heeds to re-transfer a lot less packets than the old protocol.
Note that all protocols use the same retransmit algorithm and loss detection algorithms. The only comparision is the AIMD/MIMD affect on the traffic.
And at the loss rates between the tcp and cbr streams shows there are
two regions; one where there appears to be an independance of the bg
loss rate (the island to the top left) and the other where we are getting
losses from both the sender tcp stream and the cbr background stream.
Note that the relation is not as straightforward as the tcp stream induces
loss in the cbr stream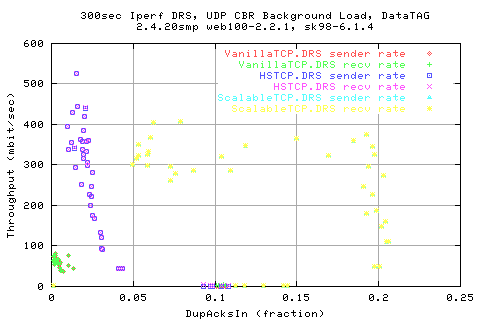
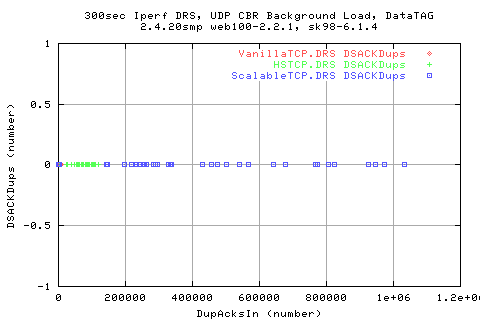
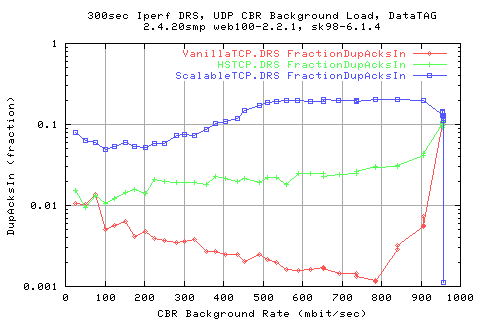
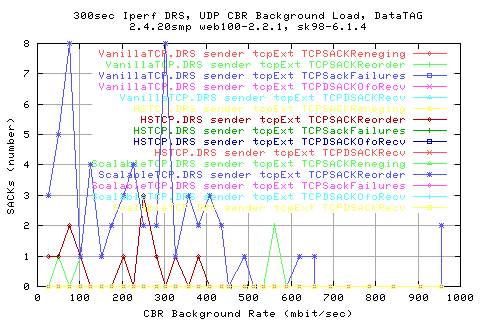
Correlating the throughput to the number of dup acks shows that there is a vague relation for the HSTCP scatter - implying that the more fraction of DUpacks we get the lower the throughput (which is true as dupacks cause retransmits and delays cwnd growth). However, there appears to be an indepence with ScalableTCP - a horizontal region and then a vertical.
![]()
Typically, three consequtive dupacks will cause a retransmit - causing the cwnd to halve. By the graph above, if we were to get solely consequetive dupacks, we should hav a graident of about 3 - however, we see taht we get a lot more dupacks than anticipated - however, there is a correlation, at least for the first half. HSTCP and Scalable (can't see with Vanilla), shows a tailing off in the correaltion - suggsting that we get a scatter of retransmits when we have low(er) number of dupacks. This region is most likely due to more consequtive dupacks - however, there is a negative relation - the less dupacks, the more fast retrans?!?!!? WHY?
![]()
Scattering the number of dupacks to the pkts retrans shows that there is even less of a relation.
![]()
Plotting it as a fraction of the packets shows nothing useful.
Another one would be to check them against congestion signals - here we see that, as with tehe fast retrans, we get a linear region and then a fallout.
![]()
As you can see, we get a linear relation between the number of FastRetransmits and the numbe rof CongestionSignals.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
{blank}
| Wed, 20 August, 2003 9:23 |
Room D14, High Energy Particle Physics, Dept. of Physics & Astronomy, UCL, Gower St, London, WC1E 6BT