

HSTCP Initial Cwnd Investigation
Goal
The goal of this investigation is to evaluate whether the implementation of HSTCP was correct. This will be conducted by sending iperf streams between UCL and CERN. The machines in question are:
- pc55: standard 2.4.16 with web100alpha1.1
- pc56: modified 2.4.16 wit HSTCP with web100alpha1.1
- pcgiga:
As we are only interested in the evolution of the cwnd between these machines, we will be looking at setting a server with 8m and the clients with 4m socket buffer size.
Note that these tests were performed on 100mbit connections at UCL.
Results
The data set can be found here for standard tcp and hstcp.
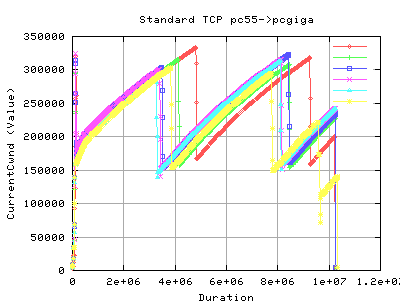
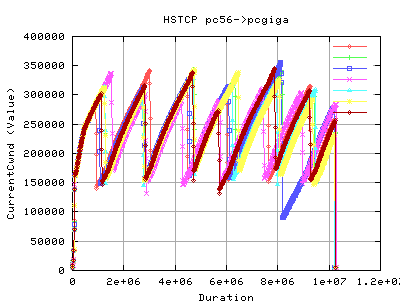
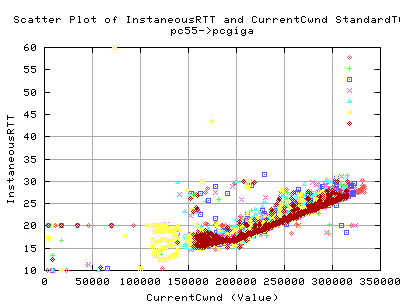
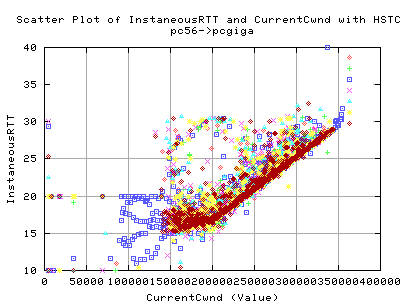
As you can see there is a marked difference in cwnd evolution. Each line on each graph constitutes a single tcp stream. Each stream was conducted tested consequtively - ie we did not allow each test to interfere with each other.
Points to note:
- The cwnd value reaches similar values on both implementations (about 340,000 kbytes)
- The frequency of sawtoothing (indicating cwnd evolution as a function of time) is much higher than that of standard tcp. In fact, we get we about 7 'peaks' wit HSTCP, whilst on 3 for STandard TCP.
We would expect that the HSTCP would have a slightly higher throughput as a result of gain in the cwnd values.
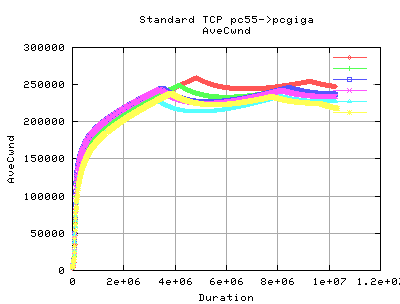
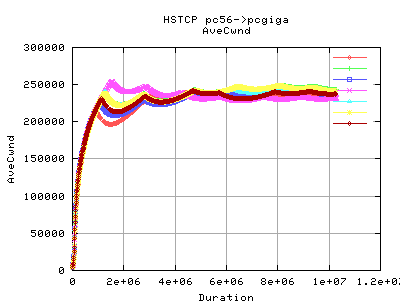
These graphs show the average cwnd during the transfer for each stream. As you can see, the difference is marked by the initial ramp up by HSTCP in the first second (after slow start). This means that the lost throughput caused by the size of cwnd limiting its transfer is decreased.
| Wed, 23 July, 2003 13:07 |
It was found that the MSS of the tcp transfers were at 1448bytes. Given this value, and that the average cwnd throughout the connections were about 240,000, we can estimate the number of segments to be about 240,000/1448 = 166 segments. The maximum cwnd we achieve is about 350,000; 350,000/1448 = 242. The lowest we achieve during transmission on average is about 150,000; 150,000/1448 = 104.
Under the Sally Floyd proposal, for any given cwnd value, we would use
the following values for a and b respectively: (note that b is in log 256,
so 128 actually equals 0.5.. etc.)
| Cwnd Value | a | b |
| 38 | 1 | 128 |
| 118 | 2 | 112 |
| 221 | 3 | 104 |
| 347 | 4 | 98 |
This would imply that we are nearly always in the second 'phase' of the HSTCP (as we use the standard parameters), and that sometimes (ie when the cwnd is above 221*1448 = 32008 kbytes) we actually get into the 3rd phase of HSTCP with AIMD(3,104/256).
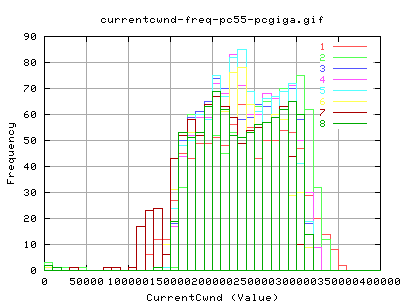
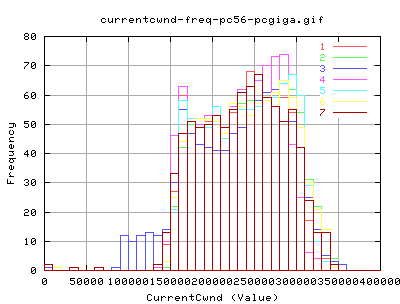
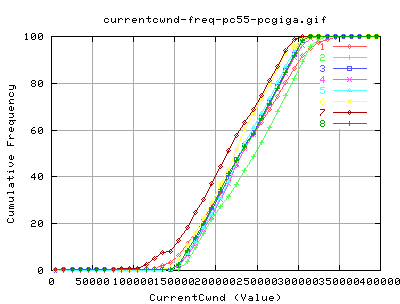
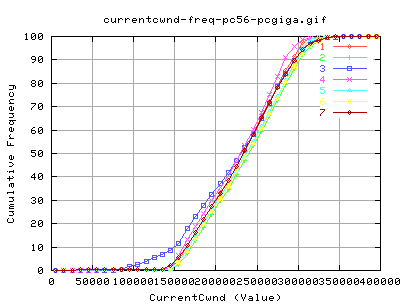
Bandwidth
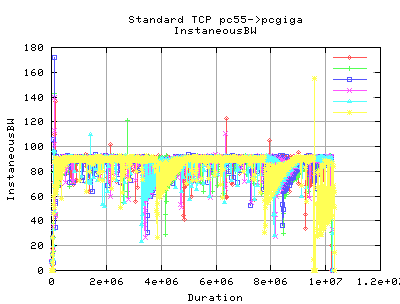
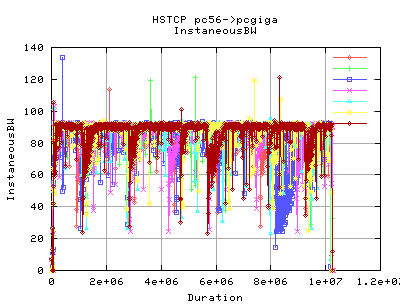
These graphs show the instaneous bandwidths as reported by web100alpha1.1 in 10millisec (approx) increments. As you can see, the variation of throughput seems to be a lot greater for HSTCP - caused mainly by the way in which the cwnd grows and shrinks. It was anticipated that the decrease in b would account for less variation in cwnd, and hence also throughput. However, this doesn't appear to be the case from these graphs by eye inspection.
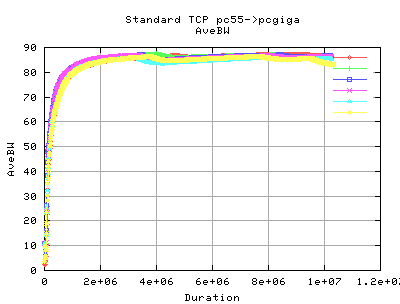
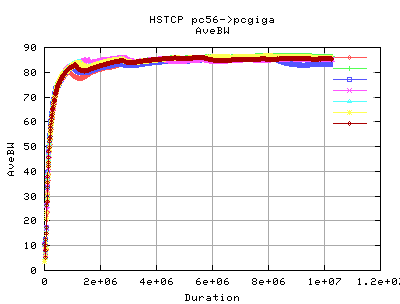
Looking at the average Throughputs as reported by web100, there doesn't appear to be much difference between the two implementations of TCP. The sudden grows of cwnd for HSTCP for 0-1 seconds appears to be outweighted by a dramatic decrease in the average throughput at just after 1 second.
Let's try to find a relation between the cwnd and bandwidths:
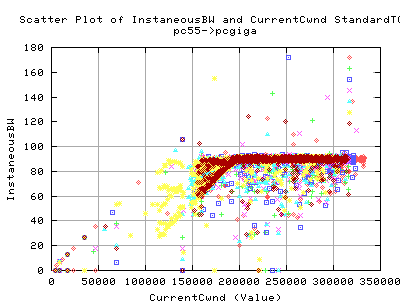
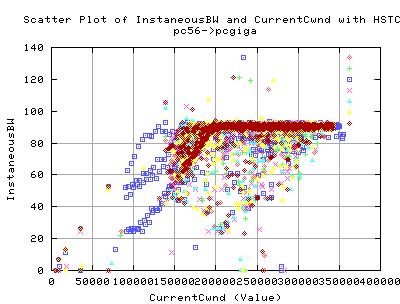
This graph shows the correlation between the Instaneous BW as recorded by Web100, and the corresponding CurrentCwnd value for that throughput.
- As you can see, there appears to be a linear correlation between the size of the Cwnd and the Instaneous throughput (although it requires some extrapolation) upto about 200,000 cwnd. This is for both StandardTCP and HSTCP. This suggests that we are still being limited by the cwnd value wrt to the throughput.
- Then past this value of cwnd (200,000), we get an independant relation between the BW and the Cwnd size. This means that even though the cwnd is growing, there is no benefit in throughput.
So why does tcp do this? There is not real advantage to making the cwnd larger than this value, and yet because more acks are coming back, it grows the cwnd until it collapses again..., thus reducing the cwnd.
Timeouts
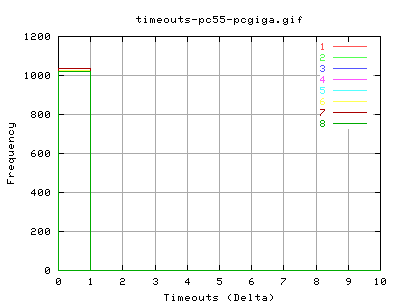
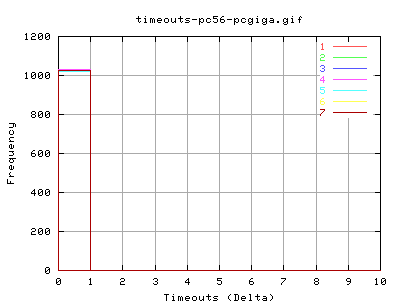
these plots show the number of timeouts per interval of 10ms. It appears that we get about between zero and one timeout every 10 milliseconds! At least it's pretty predictable... (shift the numbers over by half a bin for corresponding value frequency)
RTT
The average rtt for the tcp packets is about:
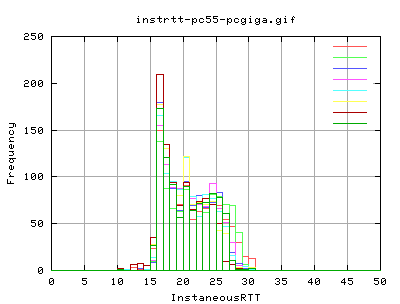
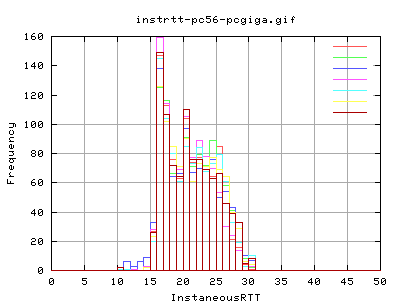
The modal rtt appears to be 16ms. However, the median value ranges between 17 to 22ms. The distribution shifted to the right hand side implies that we have a good chance of obtaining a minimal link rtt, however, we get quite a large distribution of rtt - we can expect upto about 30ms for a packet to arrive and for the corresponding ack to reach us.
Delayed ACK? How would this affect the results?
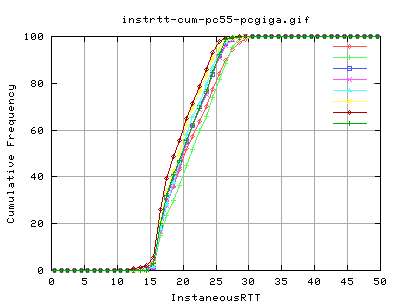
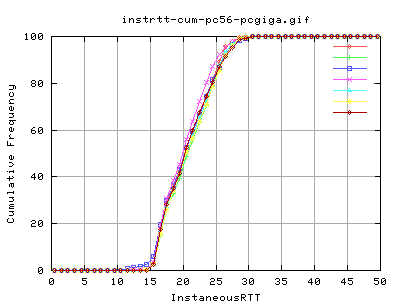
I can't really say that the distribution of rtt for hstcp is smoother as i would need a much higher number of samples to work that out.
Given that we have a average rtt of about 20ms, we will now work out the bandwidth delay product:
- bandwidth = 100mbit/sec = 12.5mbytes/sec
- rtt = 20ms = 20x10^-3s
- window size = bandwidth x rtt = 12.5 x 20x10^-3 = 250x10-3 = 256kbytes.
However, as we only get about 90mbits/sec = 11.25mbyte/sec
- windows isze = 11.25 x 230.4
The kink on the cwnd vs instaneous bw graphs is at approximately 200,000bytes = 195.3kbytes.
Even with the lowest possible rtt (modal), we get 16*10e-3 * 90/8 = 184.3kbytes - slightly less than the amount for the bandwidth delay product.
working backwards, in order to get a window of 200,000bytes, we would need, 195.3/(90/8) = 17.36ms. Which seems fair enough to the median value.
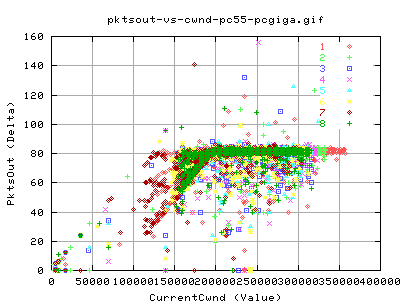
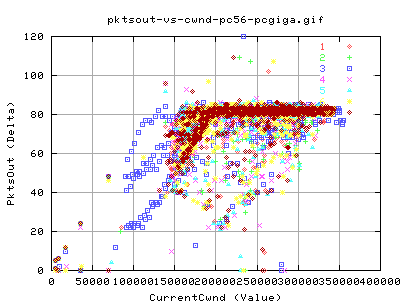
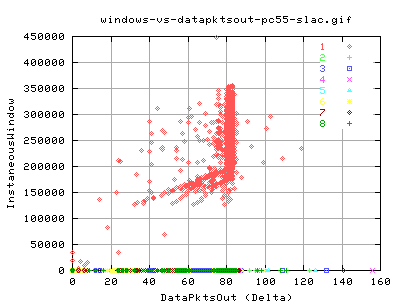
Packet Output and Throughput
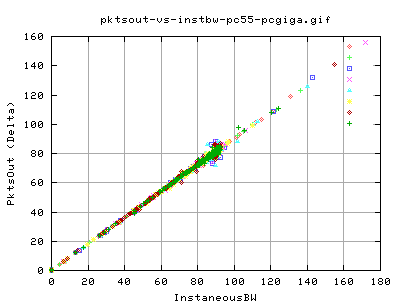
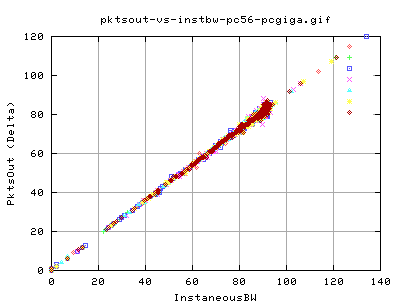
No real surprise here, there is a linear relation between the number of pkts being send out and the throughput. Notice the big cluster of points towards the 'real' peak of the throughput - indicating that even though we are flucuating a little in terms of packet output, we still get a corresponding throughput.
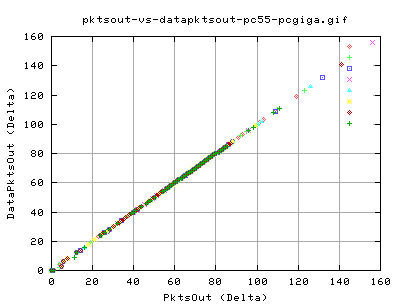
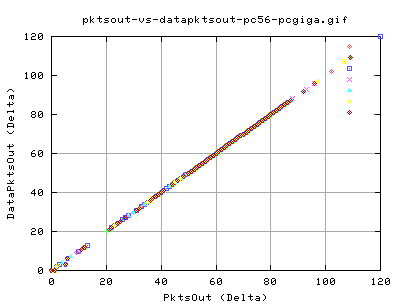
Similary, these graph show that nearly all pkts being send out are new data pkts. That is, there are hardly any retransmits in the data throughput. The only exception is at very low pkt output (less than 10 per snapshot of about 10ms).
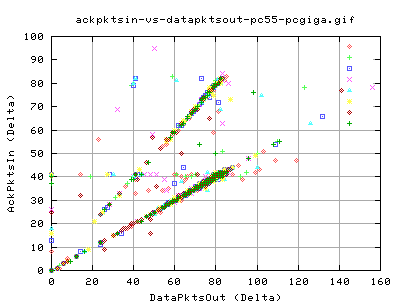
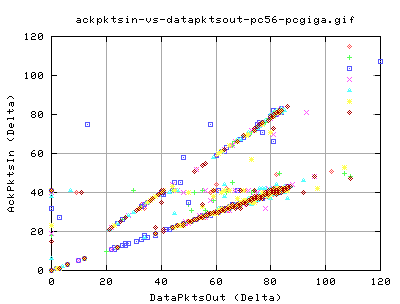
Looking at the relationship between the number of acks pkts in and the corresponding number of datapkts that were sent, we see that there are two distinct relationships between the two variables. Both relations are the same for both types of tcp.
- The lower set of points have a 1 ack for two datapkts relation - slow start
- The upper set of points have a 1 ack for 1 datapkt relation - cong avoidance
- There appears to be a faint independent of 40 ack packets having a spread in the number of data pkts.
Slow Starts and Congestion Signals
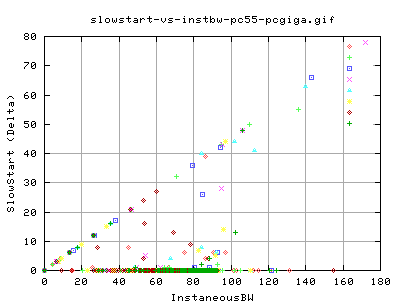
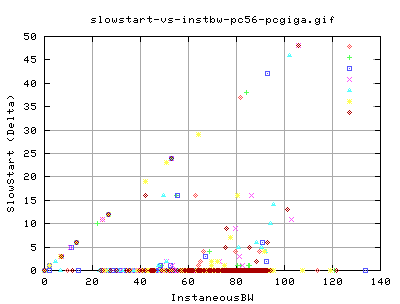
This graph shows the number of slow start events there were for each interal and the corresponding instaneousbw for that interval. There is a faint relation between the bw and the number of slow starts. Most notably, there is no real difference between the two types of tcp. This makes sense as we did not adjust the tcp slow start algorithm.
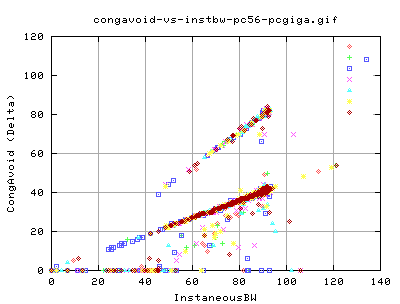
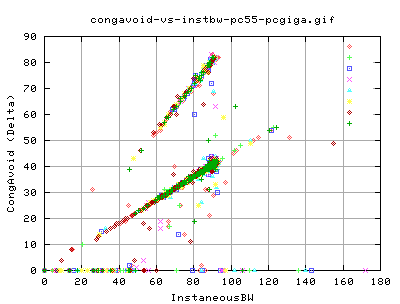
We did, however, change the congestion avoidance algorithms. But we did not change how we got into congestion avoidance. Therefore the two tcp types acheived similar results for the relation between the instaneous bw and the congavoid events. There are two distinct relationships.
- The lower relation where there is a linear increase in the number of congavoid signals and the instaneousbw
- The higher relation where we need twice the number of congestion signals for the same instaneousbw than for the lower relation
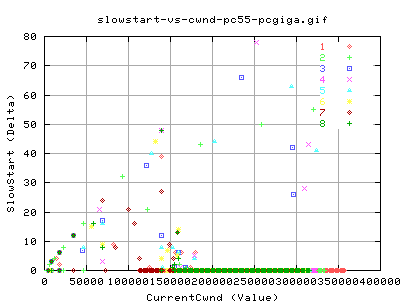
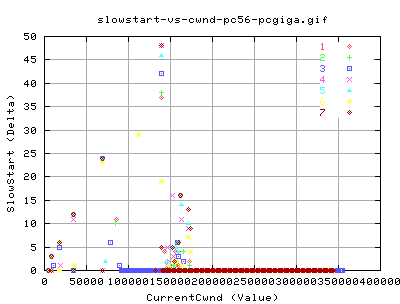
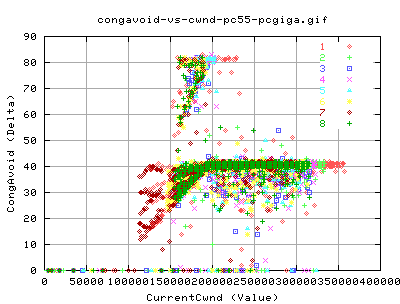
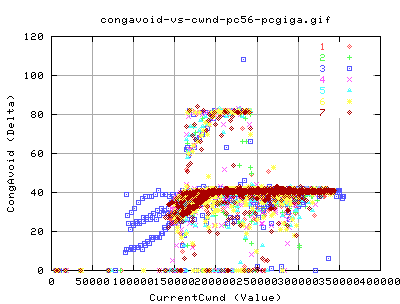
Retransmitted Packets
![]()
![]()
(un)Fortunately, there were very little in the way of retransmitted packets for this link at this time. As such, no relation can be determined (or not)
DupAcks & SACKS

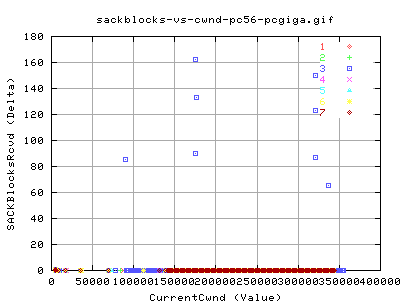
As the link is pretty clean, there wasn't much interesting data from the arrival of DupACKS and SACKS. But the absense of them implies we should get good output.
SendStalls
What are sendstalls?
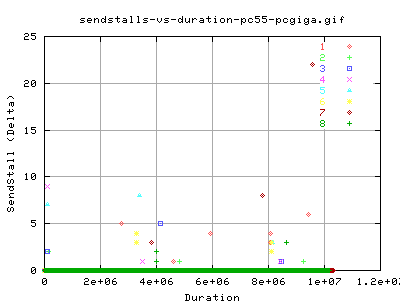
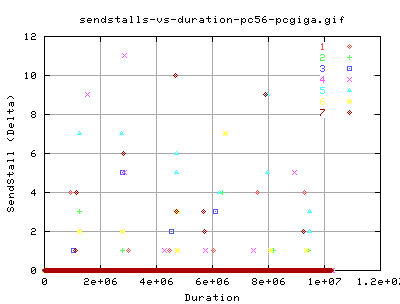
Even though we didn't get many dupacks, or SACKS, we did get quite a few SendStalls throughout the transfer.
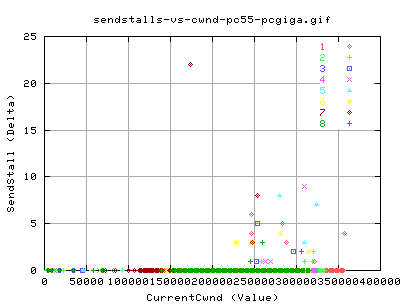
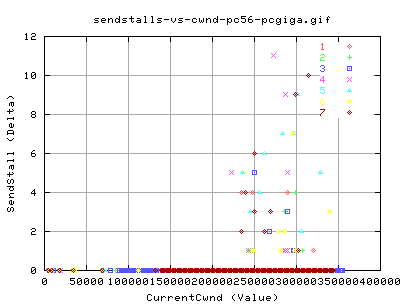
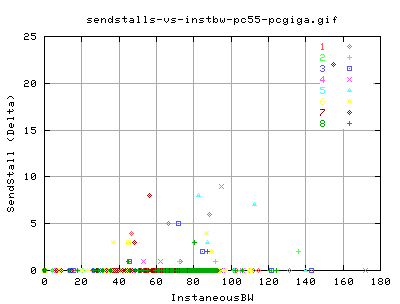
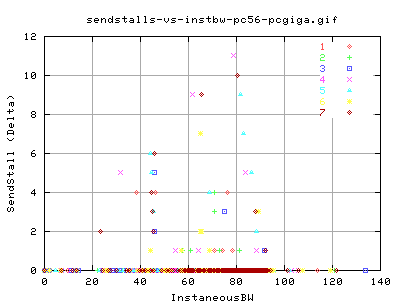
Quench
The retrans Threshold was 0.
Ack after Frast Retrasmit
DSACKDups
Rcvbuf
CurrentRcvWin
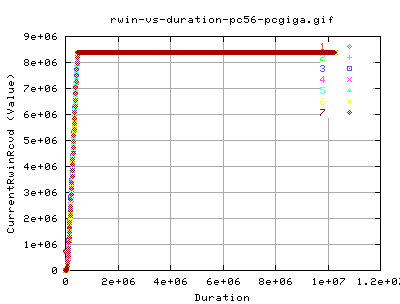
The growth of the Receiver window is as expected, growing to fill memory as discussed in [dynamimc right sizing??]. The receiver window is maintained at 8megs just before 1 second.
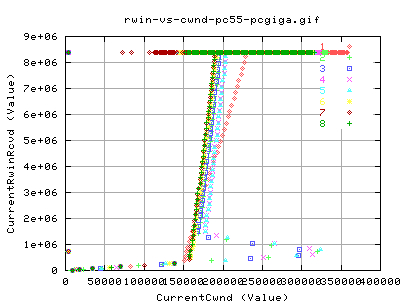
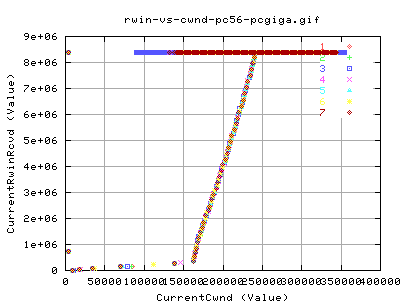
In terms of what this implies, we plot the currentrwinrcvd against the
corresponding values of the CurrentCwnd. For the most part, the relation
is independant; for a rwin of 8megs, we cover nearly all cwnd values for
both implementations.
For the other part, we see two relations:
- For cwnd 0<x<150,000
- For cwnd 150,000<cwnd<250,000
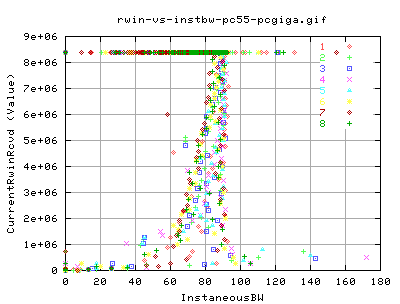
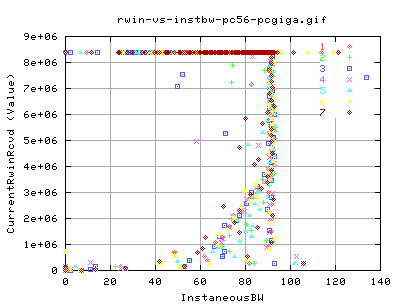
Comparing the rwin to the instaneousbw;
?
Window (Snd_nxt - Snd_una)
Snd_nxt defines the right hand pointer for the window size whilst snd_una is the point for the left hand side of the window indicating the sequence number of the lowest unacknowledged segment.
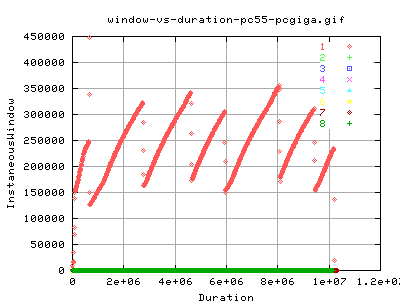
| Wed, 23 July, 2003 13:07 |
Room D14, High Energy Particle Physics, Dept. of Physics & Astronomy, UCL, Gower St, London, WC1E 6BT