

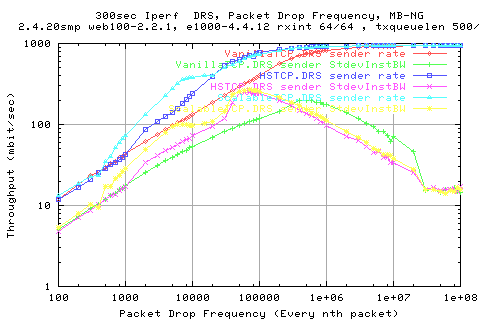
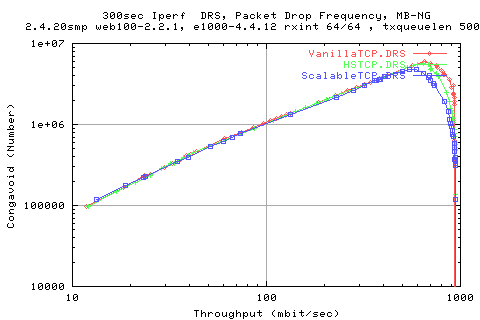
The above graph shows the thruput achieved frmo the three different stacks. We see that for high loss rates (low x axis), that they are all comparible. Then we begin to see the effects of the MIMD and alternative AIMD of HSTCP against VanillaTCP. Once we get to about 1e6 packet frequency, we see that all protocols achieve pretty much line rate.
What is strange is that the ScalableTCP implementation appears to obtain identical performance to HSTCP past about 20000 packet frequency.
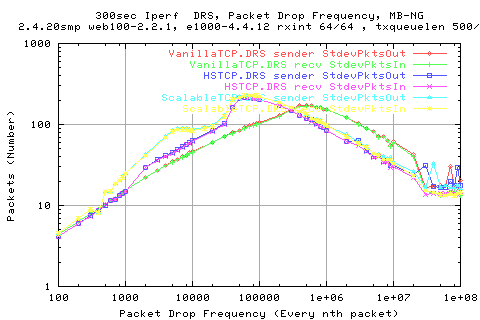
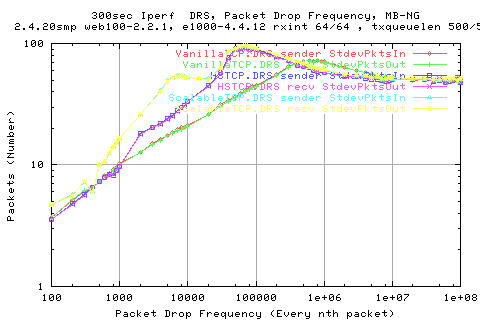
Looking at the stdev of the different stacks, we see that vanillatcp is the least variable; with ScalableTCP having the greatest variation for moderate loss rates. Then for low loss, we see that both scalableTCP and HSTCP have lower variation than VanillaTCP. WHY?
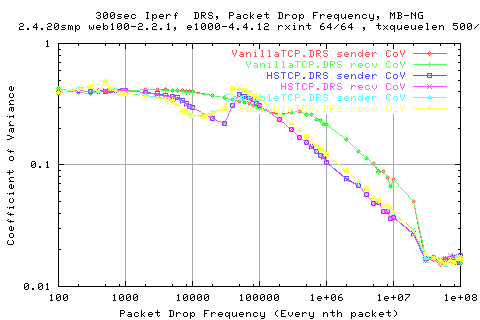
The graph above shows the CoV for each stack in each network condition. We see that again, the HSTCP and ScalableTCP stack achieves similar results. Indeed, a low CoV is preferable (CoV is stdev/thruput - high thruput , low stdev). So, this means that we actually get better performance with the two new stacks than with VanillaTCP.
Looking at the cwnd for each stack;
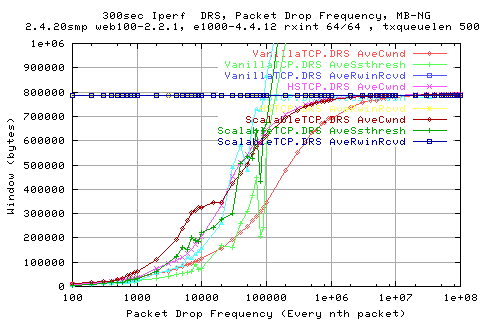
We see that VanillaTCP [Red] is much lower than the other two stacks [Pink and Brown], which would explain the lower thruputs. We also see that for high loss rates, that ScalableTCP achieves a much greater cwnd average.
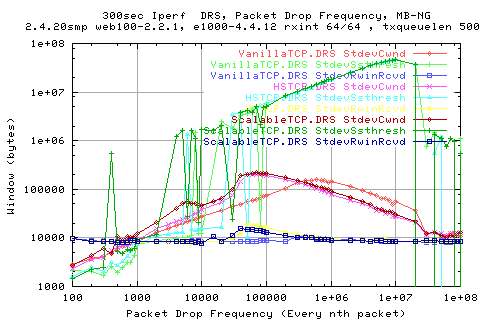
Looking at the standard deviations of the cwnds that they are similar to that of the thruputs. We also see that the ScalableTCP stack achieves higher cwnd average, but also has greater variation in the cwnd; after about 3000, we get similar behaviour to that of the HSTCP stack.
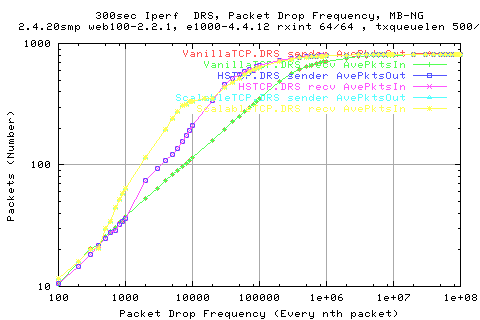
The above graph shows the average number of packets sent out per ~10ms for each stack for each drop rate. We see more clearly here that Scalable manages to shove more packets out on average out than the other stacks.
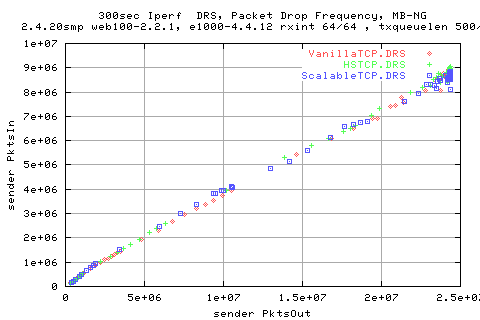
The above graph shows the flow of data packets onto the network. We see that they follow a similar trend to that of the thruput graphs (as expected).
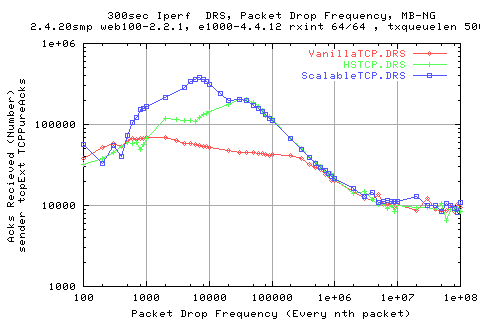
The above graph shows the flow of acks from the recv to the sender.
The above graph shows the same info as that of the two graphs before. Should we ha delayed acks, we would expect a graident of 1/2. As you can see, not only is it less (about 0.4), but as we get more packets going out, we appear to get less acks coming back (lower gradient).
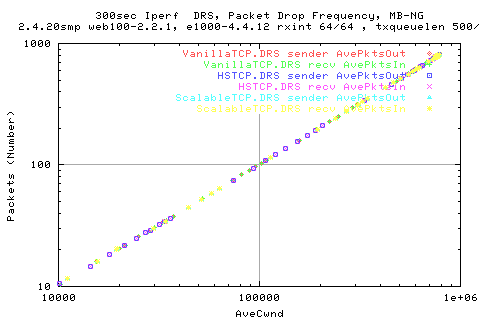
The graph below shows the relation between the cwnd size and the number of packets (average per 10ms). We see a linear relation of the two variables for all stacks.
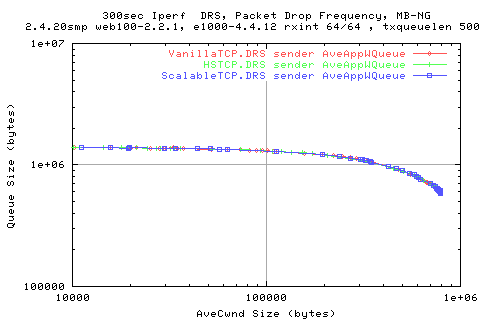
We see that the effects on the queue size is the same for all stacks when normalised to the ave cwnd size.
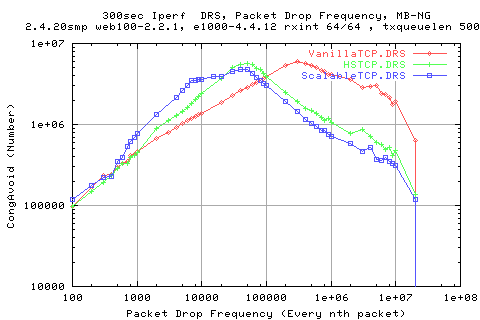
The above graph shows the number of congestion avoids experienced for each stack. We see tha the scalable implementation achieved more cong avoids than the others for high loss rates, whilst the vanilla achieves more cong avoids for low loss rates. They all end up at 0 because of the DRS and the fact that we do not send that many packets to induce artifical loss.
By plotting the number of congestion avoids against the throuput, we see more clearly the relation betwen the two variables. This is the same for all stacks. As we approach line rate, we see that the number of congestion avoids for each protocol gets less - first it is the scalable protocol, followed by HSTCP and then finally by Vanilla. This means that we actually achieve more congestion avoids for worse performing protocols at high speed.
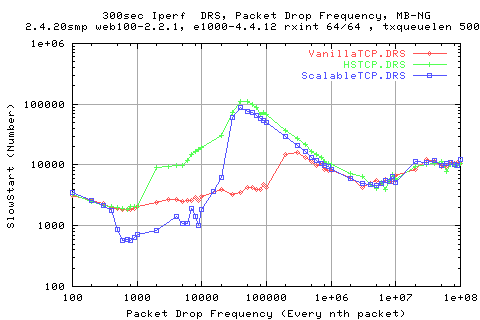
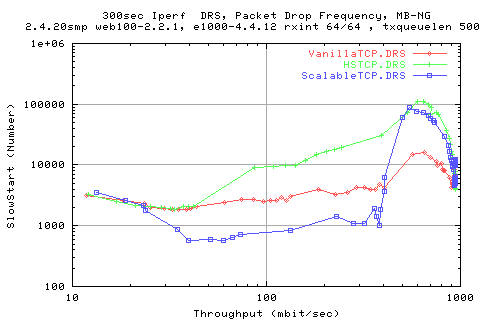
Here we see the same set of graphs for the number of slow starts. Note, as we have Moderateion of the Cwnd, we sometimes get more slowstarts even though we do not get any timeouts.
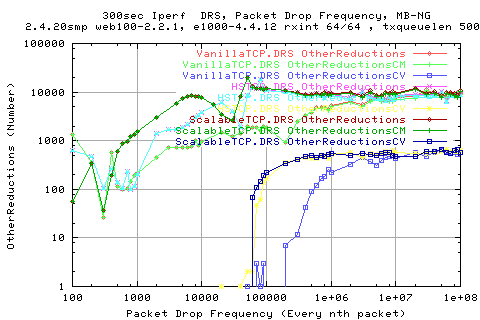
The following graph shows the number of cwnd moderations and cwnd validations in each test. Whilst OtherReductionsCV is RFC standard, OtherReductionsCM is not. We see that the magnitude of the cwnd moderations is about 10 times more than the CV's at low loss rates.
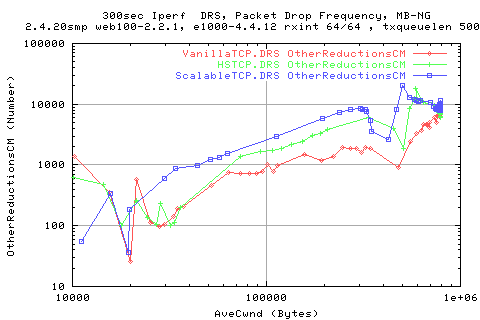
As the OtherReductions occurs when a 'dubious ack' arrives, i thoughtit might be useful to plot it against the avecwnd size;
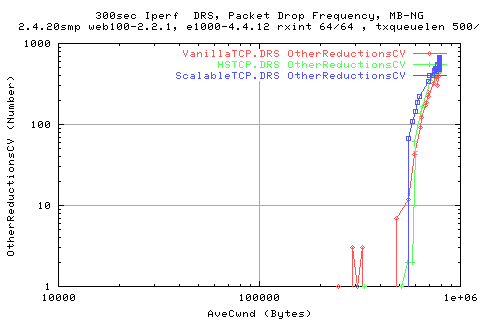
Also with CVs above.
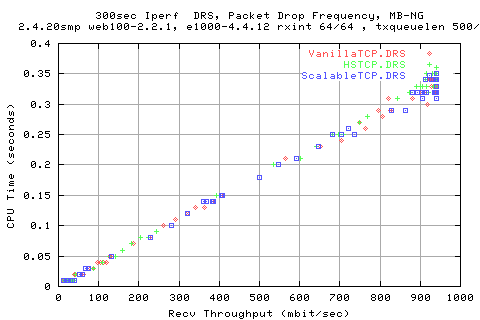
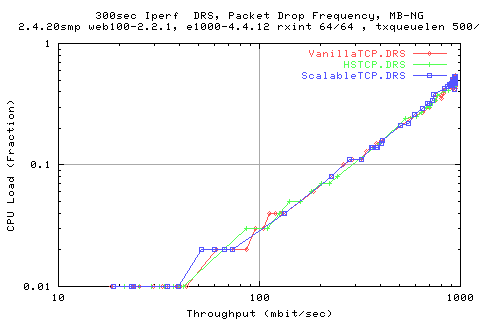
The above graph shows that there is a linear relation between the cpu load required and the throughput achieved. We see that it is approximately 50% load on a 2Ghz machines. This matches quite well to what Les Cottrell has been saying.
![]()
In the above graph, we see the relation between the numbder of FastRetrans and the number of pkts retransmitted. We see that they are vaguely linear in relation; however, the Scalable and HSTCP implementations are less so.
IS THIS THE PROTOCOLS AFFECTING ITSELF?
![]()
In the above graph, the y axis shows the number of actually induced losses at the recv. Should there be a linear relation between the two variables, we would see that all packets lost are those that are induced by the packet dropping algorithm. We see that this is not the case; there appears to be a constant loss of packets on the line (about 10) - this assumes that the loss algorithm in the TCP is perfect.
REtrans can also be induced by too many dupacks.
![]()
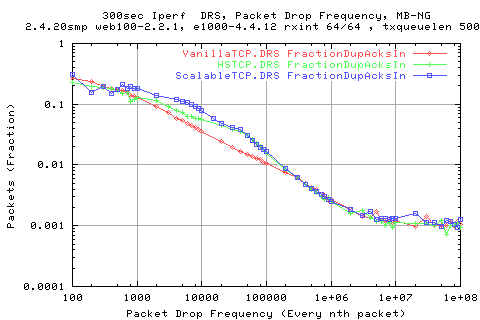
The above graph shows the ratio of packets that are retransmitted and the number of dup acks recvd.
The following graph shows the ratio of datapackets to acks recved. As you can see, they follow a similar pattern.
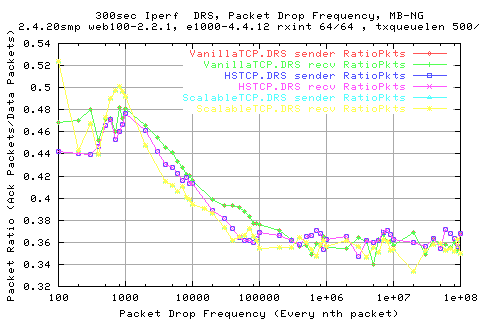
Normalising agains the ave cwnd size shows that whilst HSTCP and Scalable follow almost identical patterns, the ratio of packets is slighly less for moderate loss with VanillaTCP.
The next graph shows that all stacks cope with the retransmit of packets in a similar way. This is not surprising as they only change the aimd side of things.
![]()
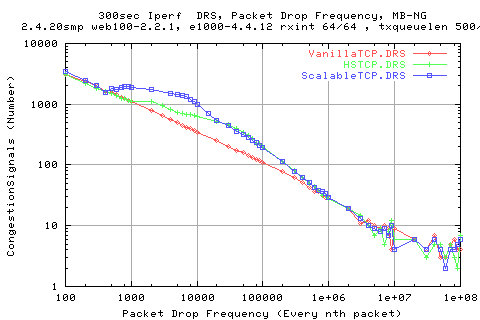
From the graph above, we see that we get more congestionsignals from the scalable stack, then hstcp. Again, we see similar results between the hstcp and scalable implementations for higher frequencies (loss).
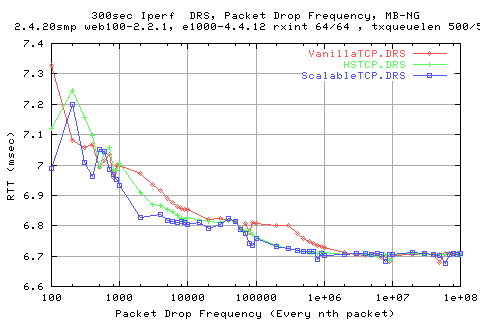
As we can see, we get higher rtts for high loss. This is suprising as we would expect the opposite as with low loss, we would be pushig more packets in to the network and hence filling the queues on the network more readily. This would increase the queue sizes and hence the per packet rtts.
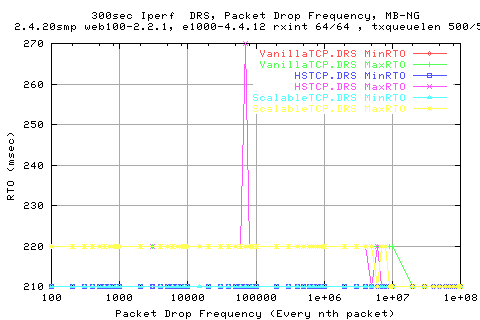
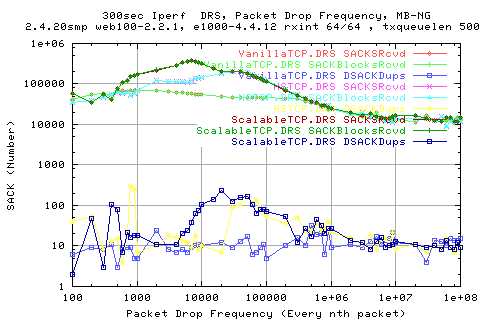
The above graph shows the reciept of sacks and related data for all three stcks.
{blank}
| Tue, 5 August, 2003 14:22 |
Room D14, High Energy Particle Physics, Dept. of Physics & Astronomy, UCL, Gower St, London, WC1E 6BT