

ScalableTCP - DRS
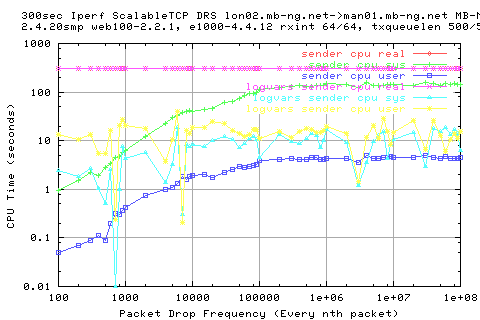
Here we see that the thruputs are quite aggressive; even under high loss, we get reasonable throughput; at least greater than in the other two AIMD based TCP protocols.
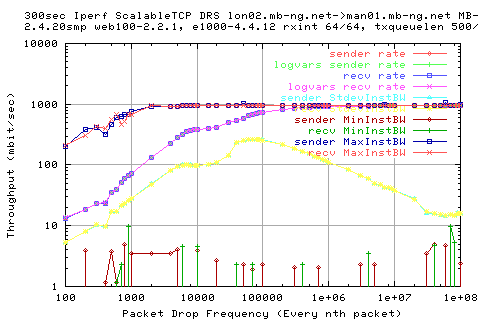
We see a strange strucutre in the stdev of the thruput however; at about 10000-50000 packets, we get a very low dip in the in the stdev of the thruput; the result of this is that the bw is rather flat as a result.
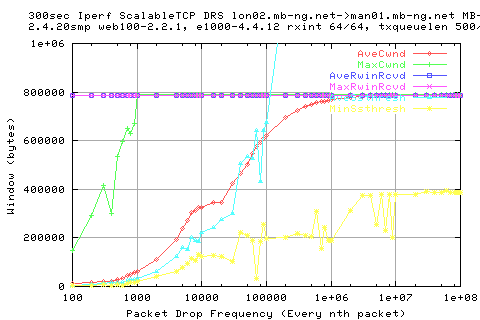
The scalable protocol states that we should reach the cwnd value approx every 1.x seconds after loss. This would mean that if we are less than this value for the packet drop frequency, we should see that the cwnd never reaches its optimal value.DOES THIS HUMP REPRESENT TAHT?
Looking at the cwnd graphs, we see that this is caused by a hump in the data for the same range;
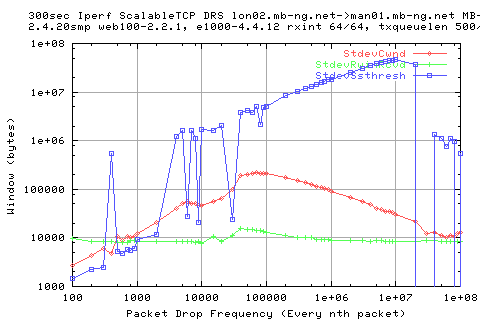
Which is repeated in the stdev of the cwnd.
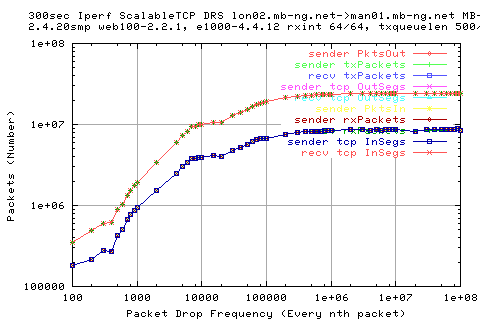
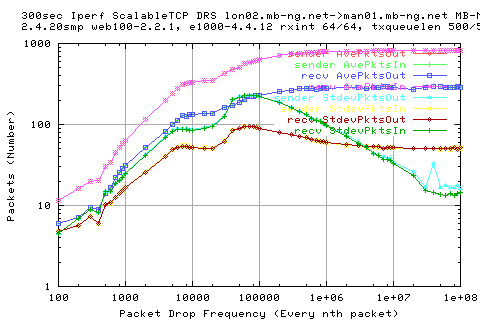
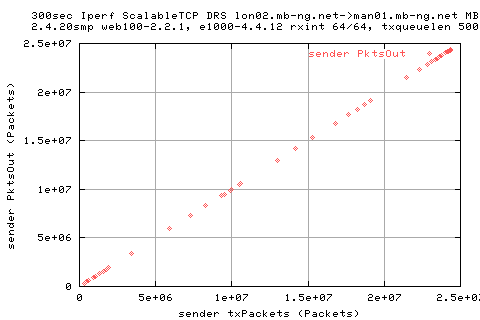
This is shows also in the number of packets and the rates of packets.
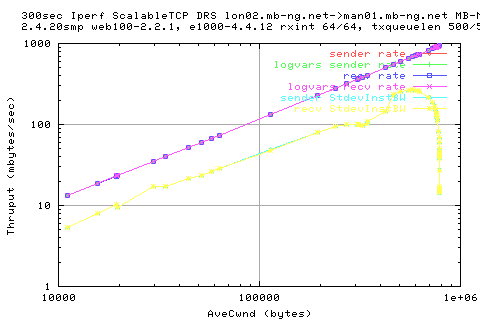
However, we see that the same relation of cwnd and thruput still holds.
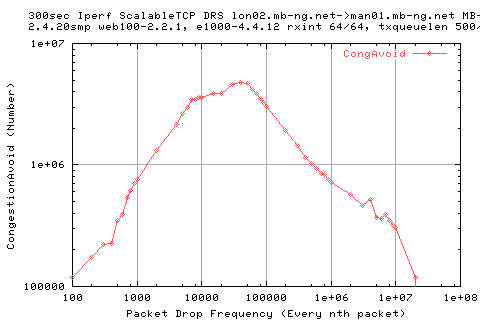
Looking at the above graph showing the number of congestion avoidances; we see that there is a flattening where the low in the thruput appears.
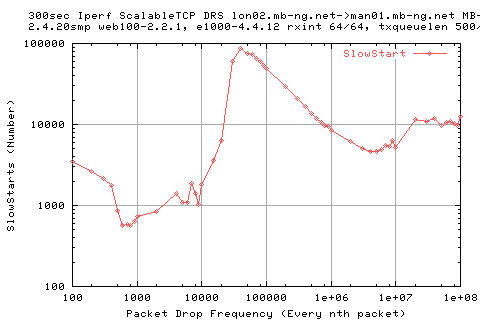
Which is matched by a sudden sharp increase in the number of slow starts experienced.
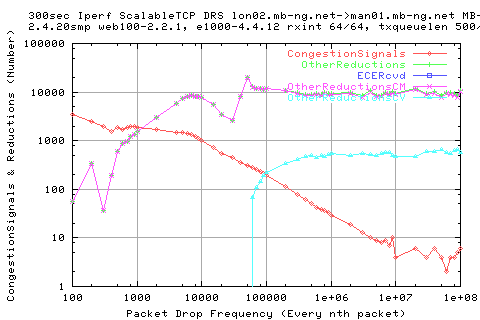
We also see that for the same region, we get less OtherReductionsCM than what the trend suggests. This would mean that the cwnd matches more correctly to the number of packets in flight and hence the cwnd doesn't need as much adjustment (negative). Therefore, we should get a higher throughput than the others.B But this is not what we see in the results. This must mean that we end up putting too many packets into the network and hence congestion ourselves.
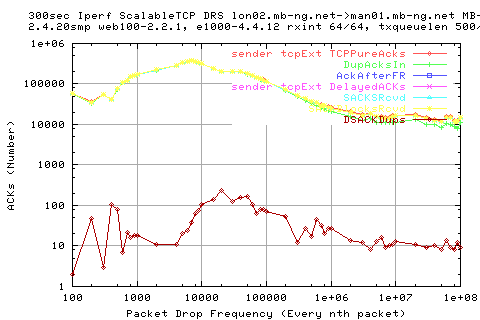
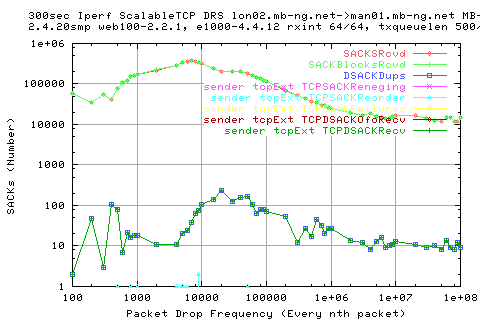
Why do we see more dsackdups?
![]()
![]()
![]()
![]()
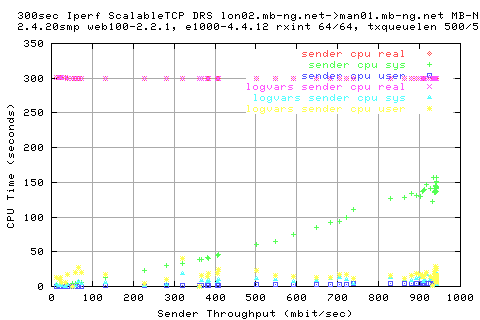
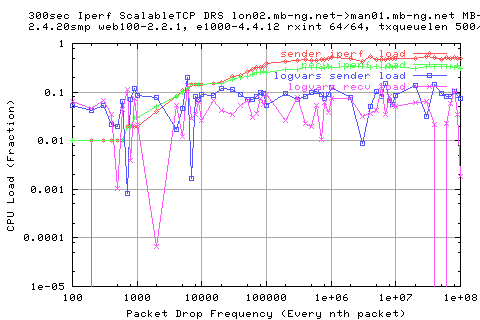
![]()
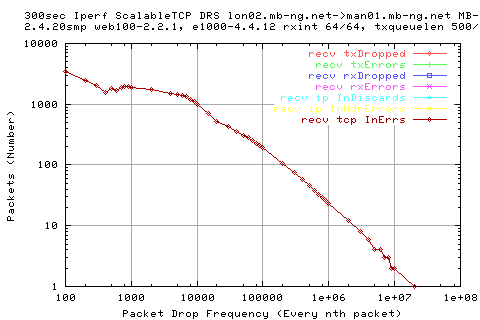
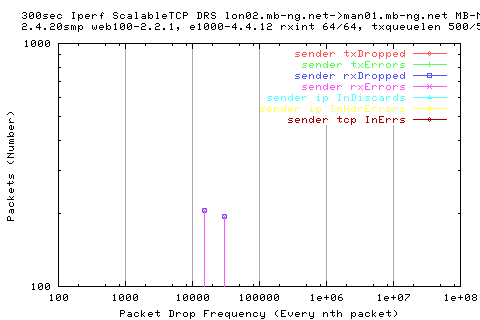
![]()
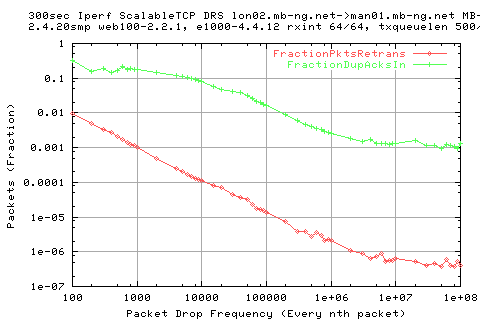
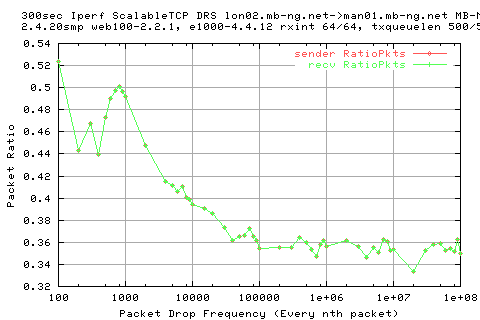
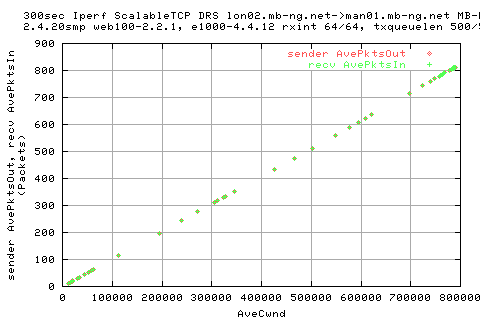
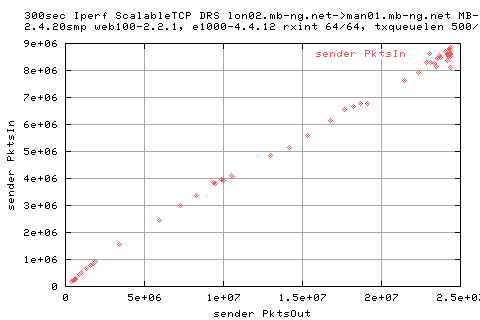
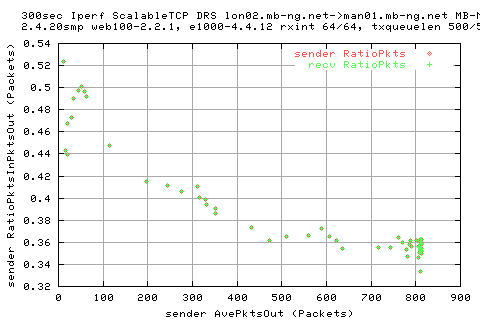
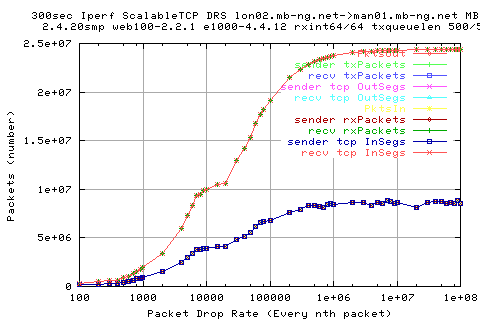
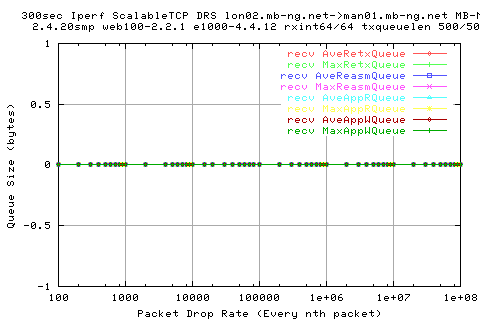
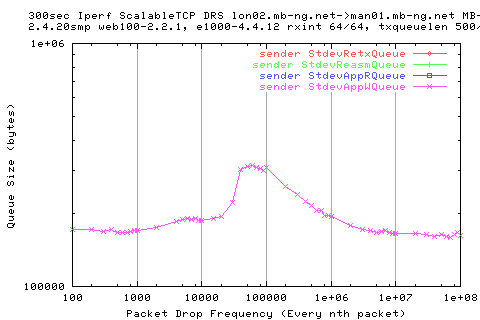
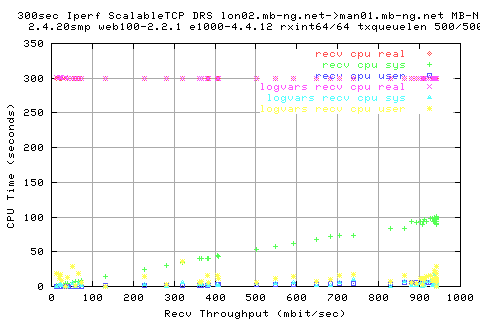
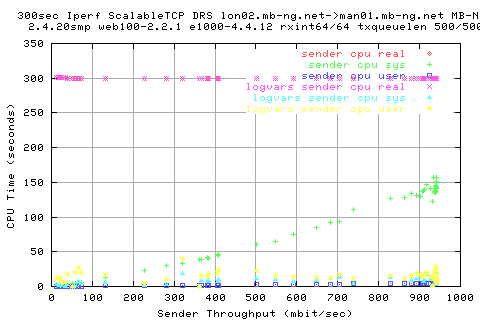
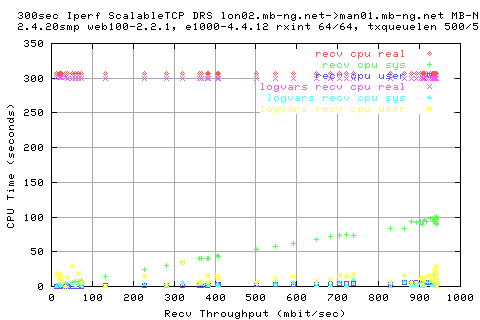
We see that there is a large variation in the sender appwqueue shortly after the hump; this suggests that the ack clocking is not working as effieciently as in the other situations.
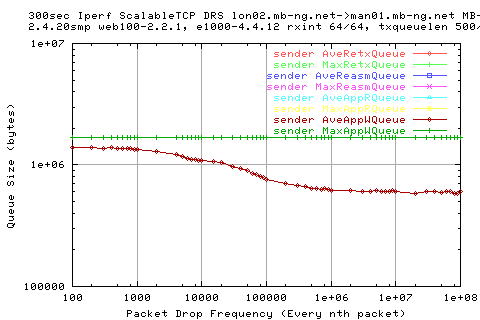
However, the ave size of te write queue is pretty consitent.
![]()
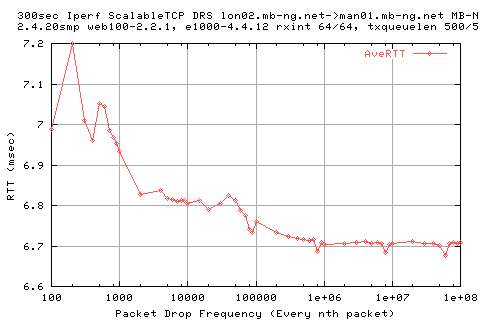
Why does RTT decrease? isn't this counter intuative? is it anything to do with rate halving? but i though the 20 kernel has rate halving built in?
{blank}
| Mon, 4 August, 2003 16:06 |
Room D14, High Energy Particle Physics, Dept. of Physics & Astronomy, UCL, Gower St, London, WC1E 6BT