

VanillaTCP with DRS
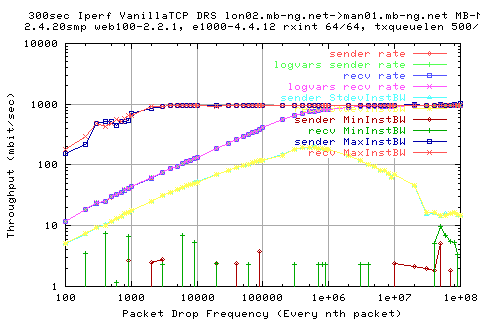
We see here that the throughput is well behaved for the various packet drop frequencies. We see that if we have a packet drop frequency of more than about 2e6 (i.e one drop every 2m packets), we can achieve line rate.
The lines we are interested in are the red-circle and the blue-square lines (it looks pink due to the overlap).
With a loss rate of about 1% (100 packets), we see that the throughput suffers a lot; only achieving about 10Mbit/sec.
The yellow line shows the stdev of the throughput (in timescales of 10ms) and shows tha the variation is quite large upto the point where we stabilise on the throughput. This then decreases and flattens off. These areas can be explained as follows;
- Initial ramp up; each packet drop frequency is proportional to amount of time between packet drops. As such, when we increase the packet drop frequency, we allow the cwnd to grow larger each time; hence a linear increase in the stdev.
- Initial fall off; as we using DRS, we would spend more time at the same value of cwnd (=recv window), therefore, we have managed to grow the window to the size of the recv window. The fall off is due to the fact that we maintian the same value for longer, and hence the stdev is less.
- Final Plateau; as we are only transferring for 5min, we can transfer a max of 83,000x300 packets; which is larger than the packet drop frequency.
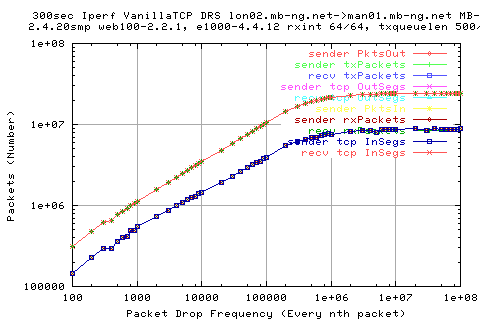
This graph shows the absolute number of packets that are sent for each test. As expected, we can't send out faster than line, so we are limited by the number time.
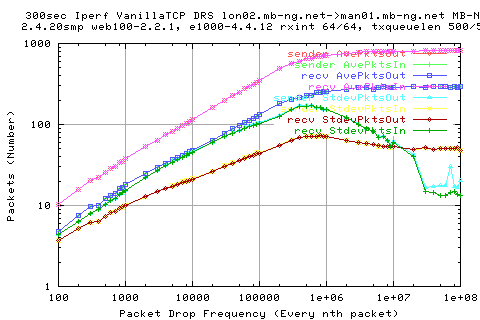
This graph shows the average rates per 10ms (approx). We see that the standard deviations from the packet output (sender out and recv in) matches that of thruputs. The ack data, on the other hand, is more stable; and plateau's off soon after the peak rates. This is due to the fact we can only ack a proportion of packets which are recieved. As such, the rate in which the acks are sent back is proportional to the rate in which packets are recved. As the rate of packets (data) is constant(ish), then so is the stdev of the acks. It falls of a little as there are a number of acks which aren't sent out due to lost packets. This difference becomes zero as we go past the 2e7 packet drop rate.
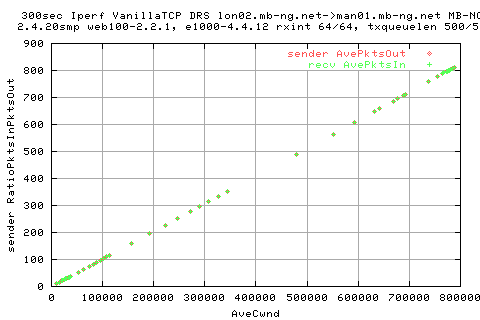
This graph shows explicity that we are entirely limited by the cwnd in terms of number of pkts leaving the interface. It'sa very linear relationship.
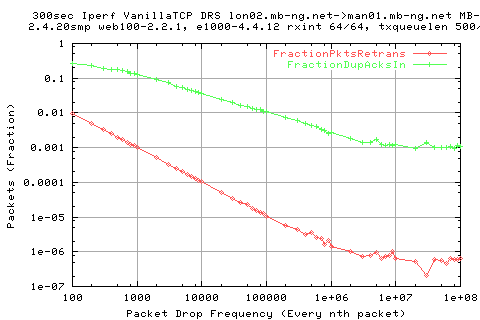
This graph shows the faction of packets which were retransmitted. As expected, these numbers are directly related to the packet drop frequency. Notice that we get a lot more dupacks; we should get three times the number of dupacks than the numbe rof lost packets (assuming no reordering).
![]()
The above graph shows the two lines in the previous graph against each other. There appears to be three regions:
- A very sharp increase in the number of dupacks to the number of retransmitted packets
- A region of about (70000-40000)/(800-50)=40 dupacks per pktsretrans....??
- A negative region where the number of dupacks gets less with the number of pkts retrans.
WHY?
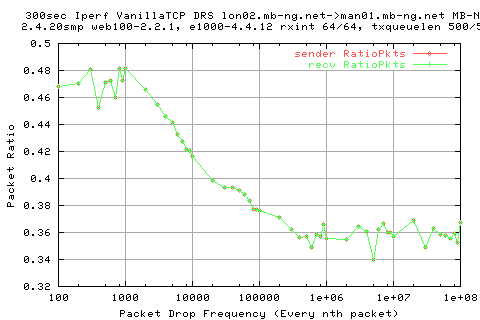
The above graph shows the variation in the PacketRatio (ie Number of Packets In/Number of Packets Out) at the sender and vice versa on the recv. The assumption is that given delayed acks, we would always have a packet ratio of 0.5. As you can see on the graph, this is not the case.
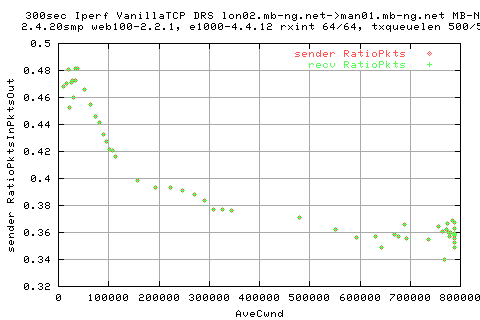
This graph shows the same but against the average cwnd value. Hmm... think i might need to look into the code for this...
![]()
The above graph simply shows the number of pkts that were retransmitted and the number of FastRetrans. We see that approximately for every Pkt retransmitted, we have one FastRetrans; ie for every instance of a FastRetrans, we retransmit one packet. This can be better seen in the graph below;
![]()
This suggests that the FastRetrans algorithm is well suited to single packet loss under the conditions of this test.
If we plot it so that we see the number of induced drops (recv_tcp_InErrs) against the pktsretrans, we see that there is almost a one to one relation. This implies that the retransmission algorithms are efficient and the losses due to other factors apart from the induced recv loss (ie bit corruption on the line) are minimal.
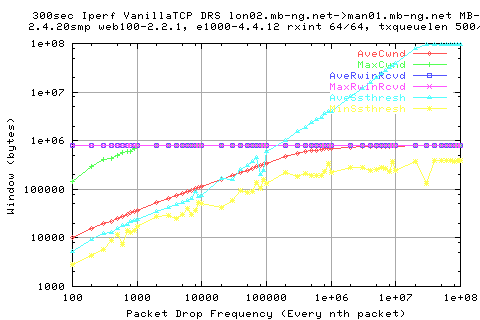
The aboe graph shows the variation of the various windows in tcp. Note that the AveSsthresh values may not be representative as i've taken away from the array in each run the initial value of ssthresh. This is because linux holds the initial value of ssthresh as 4billion. Therefore, if we have an undo in this period, the value may seem larger than it actually was.
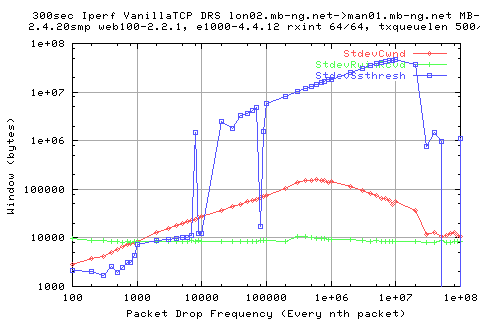
Hre we see the varition of the various windows; we see that the recv_window is virtually constant; not surpising since it's DRS (with it's minimum at the socket buffers + overhead). We see that what we said earlier about the ssthresh holds thru here because we see large variations in the stdev due to the inclusions of the initial value(s). We also see that the cwnd stdev varies just like that seen in the thruput graph. This implies that the cwnd has a direct consequence in the ouput of packets and hence the thruput (obviously).
Quite simply, we see that the the ave cwnd curve follows closely to the thruput achieved. This is shown below:
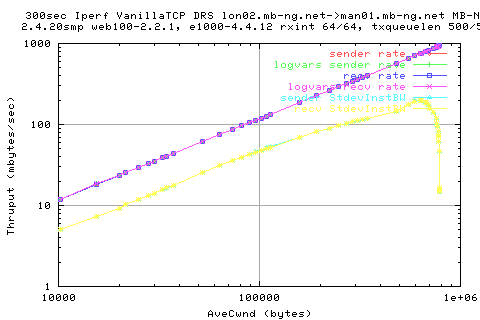
We see that there is a linear relation between the avecwnd size and the thruput achieved. The standard deviation becomes less as we get to higher avecwnd; this is due to the capping of the cwnd due to DRS.
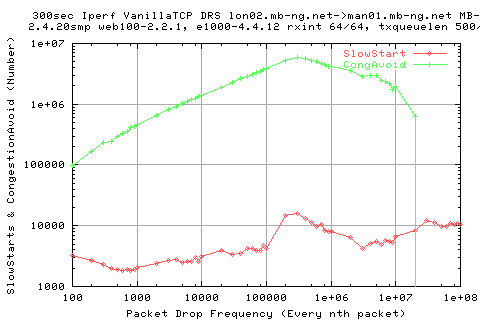
From the above graph, we see that the number of slow starts steadily increase; this is strange as we should only see slow start initially; and it should take approximately the same number of packets each time (as long as the drop rate is larger than this number). The graph is showing the trend that as we increase the pkt drop frequency (err.. nth packet) then we get more and more slow starts. This, after a little investigation is due to the fact that we are getting OtherReductions_CM which cause the cwnd to drop; sometimes below the ssthresh value and hence slowstart occurs.
The following graph shows the variation in teh AveRTT as measured at the sender. Note that this is prone to resolution inaccuracies.
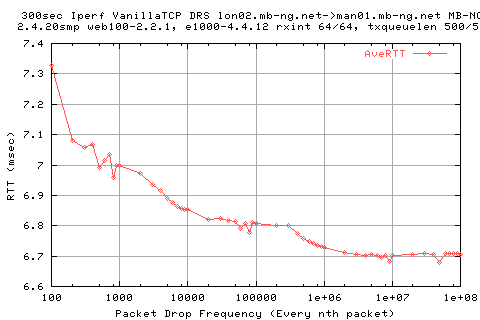
EXPLAIN: Why does the RTT appear to decrease with less packet drops?
RTTVAR <- 3/4 * RTTVAR + 1/4 * | SRTT - R|
SRTT <- 7/8 * SRTT + 1/8 *R
RTO <- max( SRTT + 4*RTTVAR, 1s );
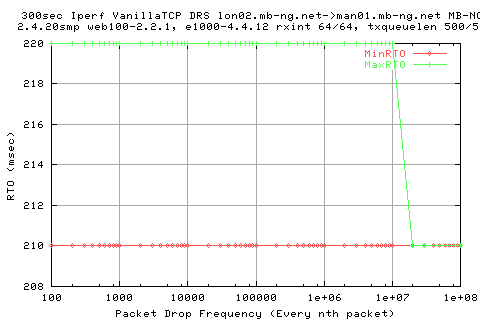
We see that the RTO's are pretty much constant throughput; this is due to the combination of very small RTTVar a the fact we don't actually get any timeouts occuring for these tests.
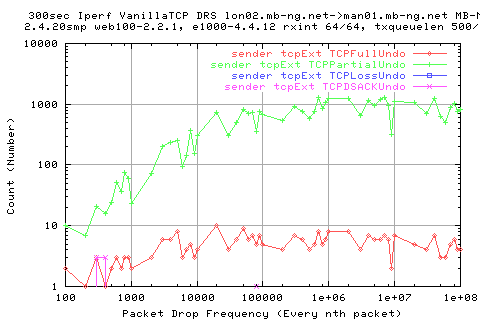
The graph below shows the number of Undo's initialled by the linux kernel.
This following graph shows the reductions in the kernel. As you can see, the number of CongestionSignals decrease as we lose more packets. This makes sense as the feedback from the network is more; ie we don't loose any packets which cuase the congestion signals to occur.
OtherReductionsCM appear to be the most frequent cuase of cwnd reductions. This value appears to increase as we decrease the drop rate.
Cwnd Validations appear to increase substantially once we are being capped by the DRS recv window. WHY?

These following graphs show the size of the socket buffer queues in tcp. We see that as we increase the nth packet drop frequency, we get a smaller AveAppWQueue. This makes sense as the queue size should be dependant on the number of packets lost.
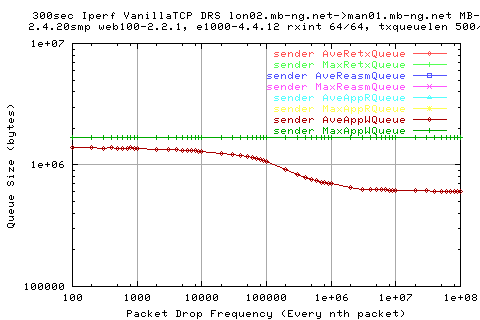
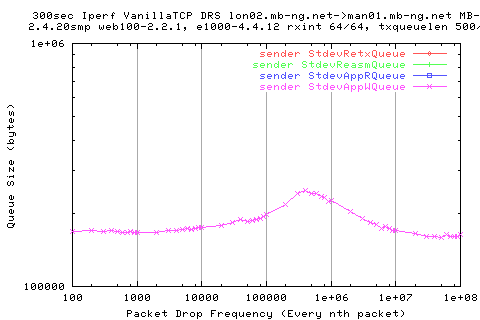
We see that the stdev of the AppWQueue on the sender is at its greatest when we have a value of pkt drop frequency similar to that of when the stdev recv pkts in is greatest. This value is also the same as the stdev of sender outs out. So when the variation of pkts leaving the sender is the greatest, we get larger AppWQueues.
| Tue, 29 July, 2003 16:07 |
Room D14, High Energy Particle Physics, Dept. of Physics & Astronomy, UCL, Gower St, London, WC1E 6BT